flowchart TD
LM["Dump Language Model GPT2"] -->|"Randomly generates output "| P
P("$$p=\frac{1}{50257}$$")
P --> L1("$$ L = -ln(p) $$")
L1 --> L2("$$ 10.82 $$")
Büyük dil modelleri giriş
Resume Atilla Özgür
- polyglot programmer
- database developer
- build engineer
- researcher
Resume Atilla Özgür Professional
- Started programming in 1991, high school
- Graduated in Electrical Engineering in 2003 from best Technical University in Turkey METU
- 22 years of Professional Software Development experience
- 6 years is Project Management and Team Leading experience
- 7 years of Database Administration experience
- 6 years of AI and optimization Algorithm development for Steel Factories
- 1.5 years of GenAI-LLM experience
Resume Atilla Özgür Professional
- Worked with different web application development platforms and Database Systems
- I have numerous Microsoft certifications (MCPD,MCSD,MCT)
- I am certified in Oracle (OCA 11g) and SQL Server (2000-2008) Databases.
- Worked with a lot of different programming languages professionally and academically
- C#
- Java
- Python
- Visual Basic
- javascript
- SQL
- R
Resume Atilla Özgür Academic
- Bachelor Degree in Electrical Engineering in 2003 from best Technical University in Turkey, Middle of Technical University
- Master of Science in Computer Engineering in 2008 from Atilim University, Turkey
- PhD in Electrical Engineering in 2017 from Baskent University, Turkey
- My thesis was was about machine learning, optimization and intrusion detection systems
- I used python, matlab, groovy, weka in my thesis
- My first post-doc work was about machine learning and optimization for steel production systems.
- My second,current, post-doc work in Constructor University is about LLMs for requirement management/contract handling
Education
| University | Department | Degree | Start | End |
|---|---|---|---|---|
| Middle East Technical University | Electrical Engineering | Bachelor | 1995 | 2003 |
| Atılım University | Computer Engineering | Master | 2004 | 2007 |
| Middle East Technical University | Medical Informatics (Incomplete) | Master | 2005 | 2008 |
| Başkent University | Electrical Engineering | PHD | 2007 | 2017 |
Employment History
| Title | Company | Start | End |
|---|---|---|---|
| Postdoctoral Researcher | Constructor University Bremen - Mathematics and Logistics | 04/2024 | - |
| Adjunct Professor (Part time) | Ankara Science University | 09-2024 | 02-2025 |
| Senior Developer | SMS Digital | 02-2022 | 03-2024 |
| Adjunct Professor (Part time) | Constructor University | 09-2022 | 02-2024 |
| Assistant Professor | Ankara Yıldırım Beyazıd University - Computer Engineering | 06/2021 | 02/2022 |
| Postdoctoral Researcher | Jacobs University Bremen - Mathematics and Logistics | 01/2018 | 01/2022 |
| Database Administrator | Turkish Labor Agency | 07/2011 | 12/2017 |
| Software Developer and Build/DevOps Engineer | Milsoft | 05/2010 | 07/2011 |
| Senior Software Developer | Tilda Telekom | 10/2009 | 05/2010 |
| Software Trainer | Freelance | 06/2009 | 10/2009 |
| Software Project Manager | Turksat | 07/2008 | 06/2009 |
| Software Project Manager | Simetri | 09/2006 | 04/2008 |
| Software Trainer | Netsoft | 10/2005 | 12/2006 |
| Software Developer | Kale Yazılım | 10/2004 | 10/2005 |
| Software Developer | Veripark | 06/2003 | 10/2004 |
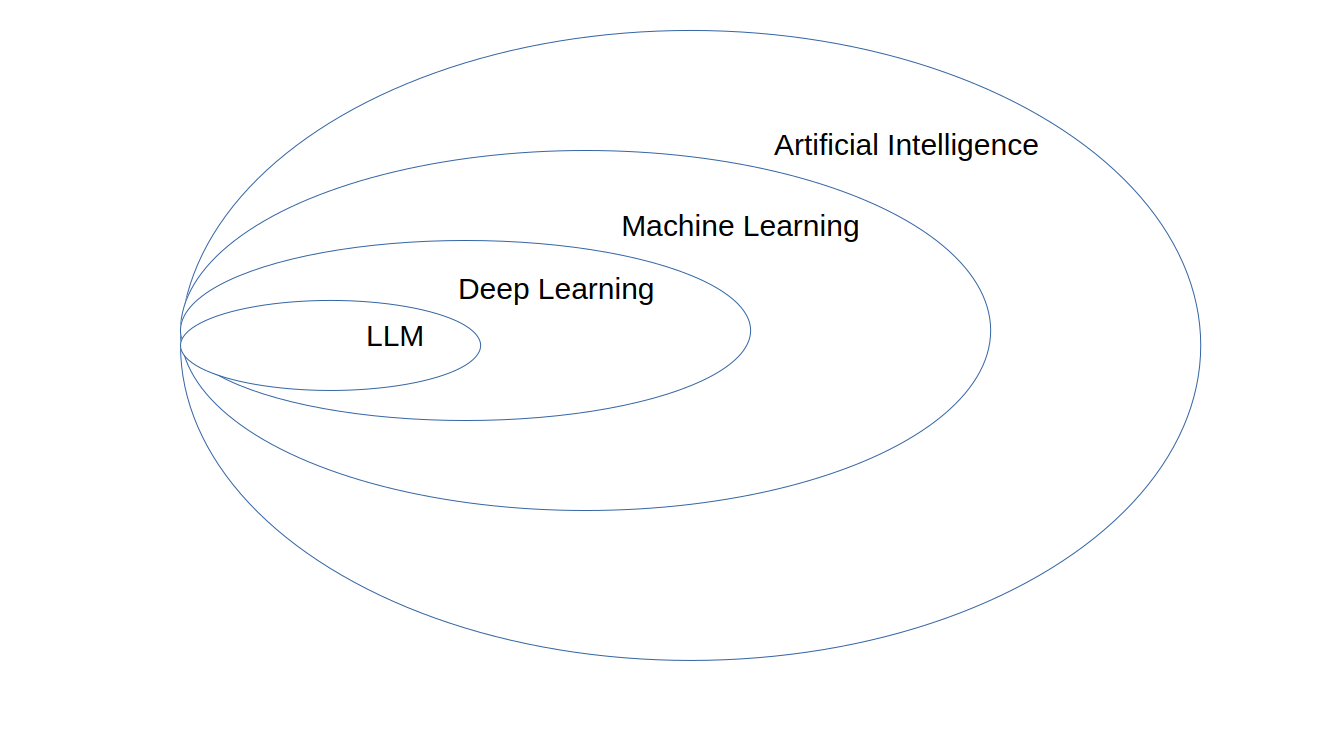
Broader AI
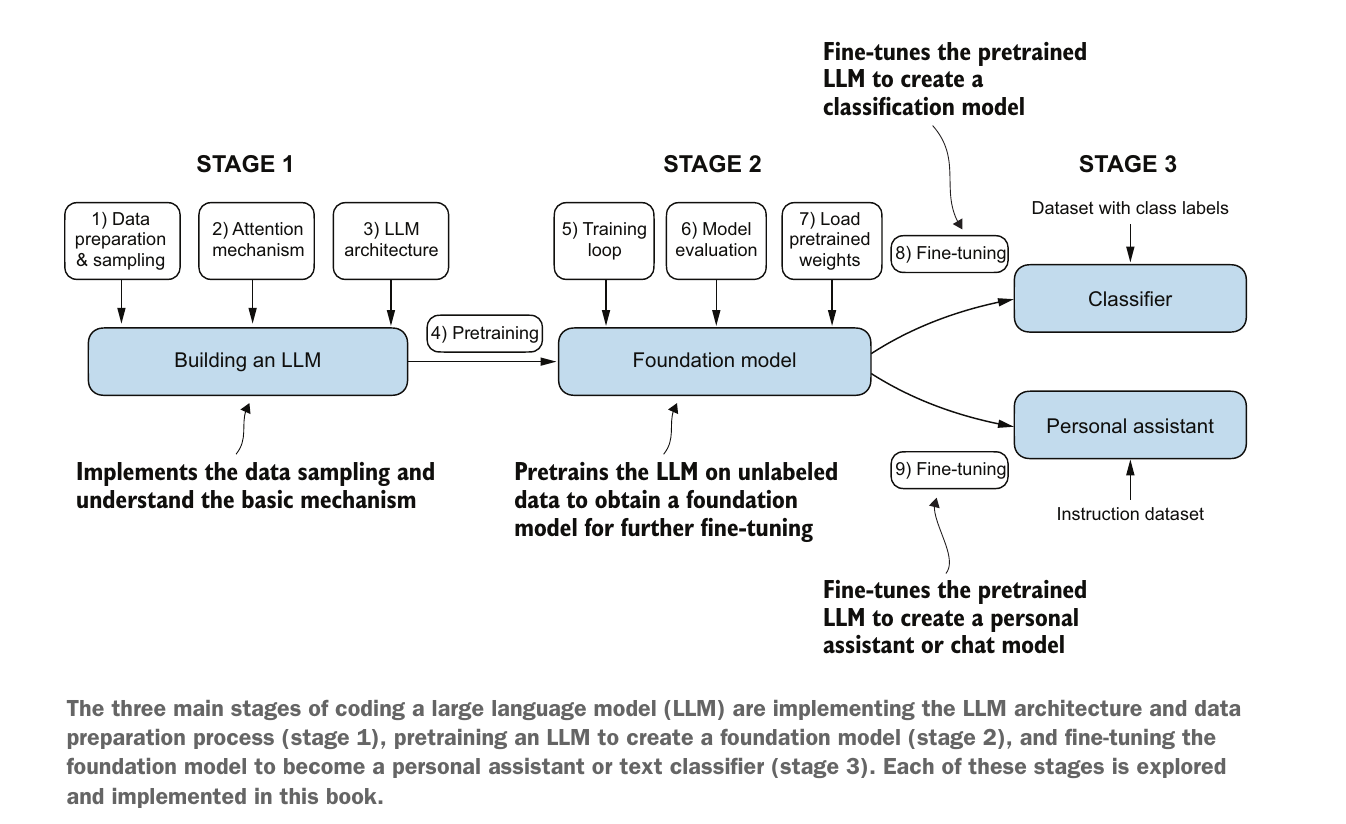
Course contents for LLM
Course book
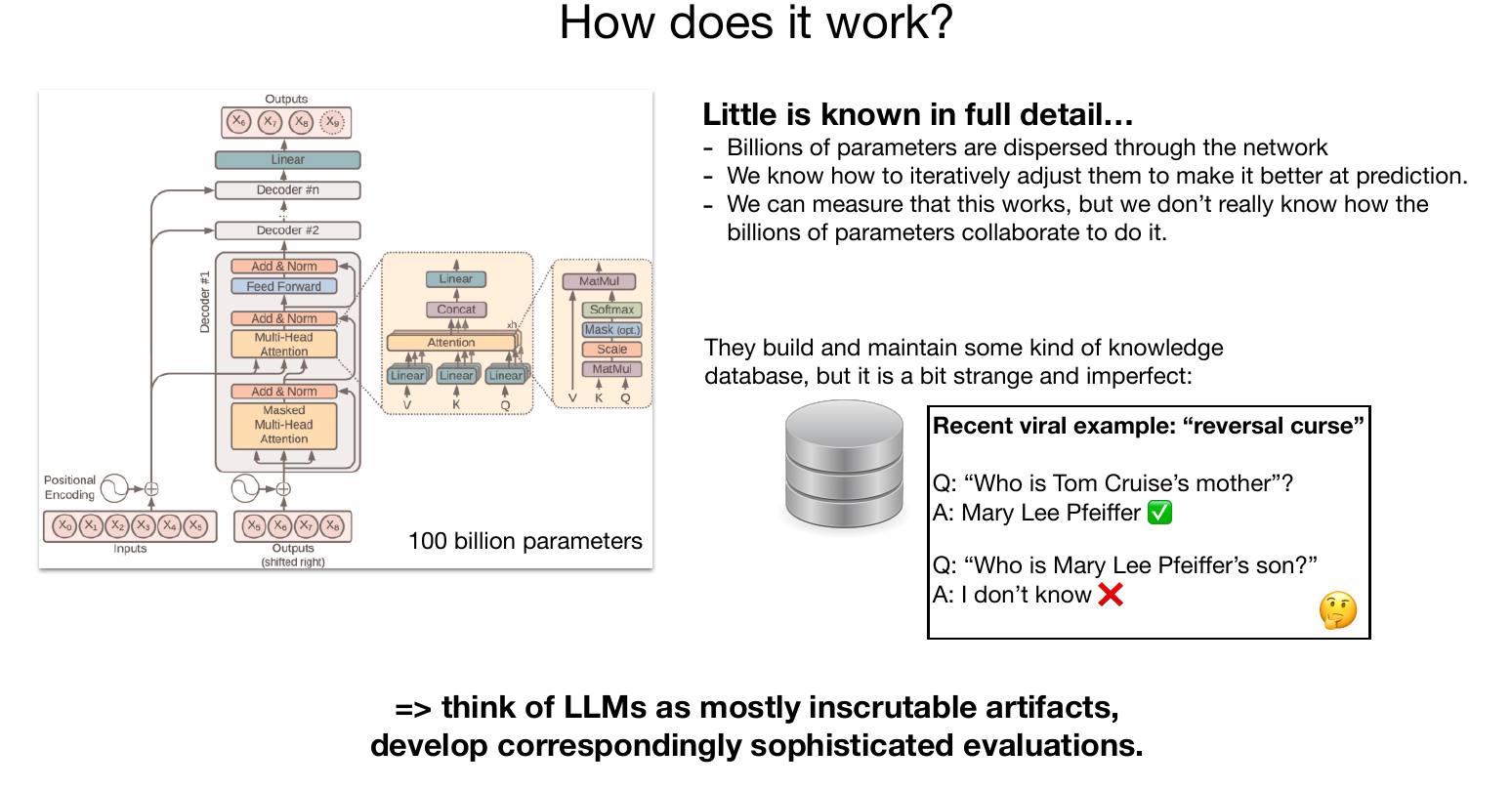
How Large Language Models (LLMs) work
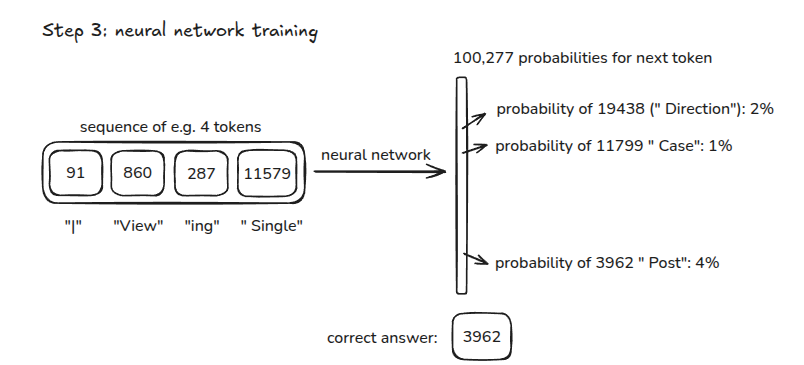
LLMs are built using supervised learning. They repeatedly predict next words using previous words.
My favorite food is a Döner with spicy souse
| Input A | Output |
|---|---|
| My | favorite |
| My favorite | food |
| My favorite food | is |
| My favorite food is | a |
| My favorite food is a | Döner |
| My favorite food is a Döner | with |
| My favorite food is a Döner with | spicy |
| My favorite food is a Döner with spicy | souse |
How Large Language Models (LLMs) work 2
Stochastic Parrots
- the term stochastic parrot is a disparaging metaphor, introduced by Emily M. Bender and colleagues in a 2021 paper, that frames large language models as systems that statistically mimic text without real understanding.

Neural networks
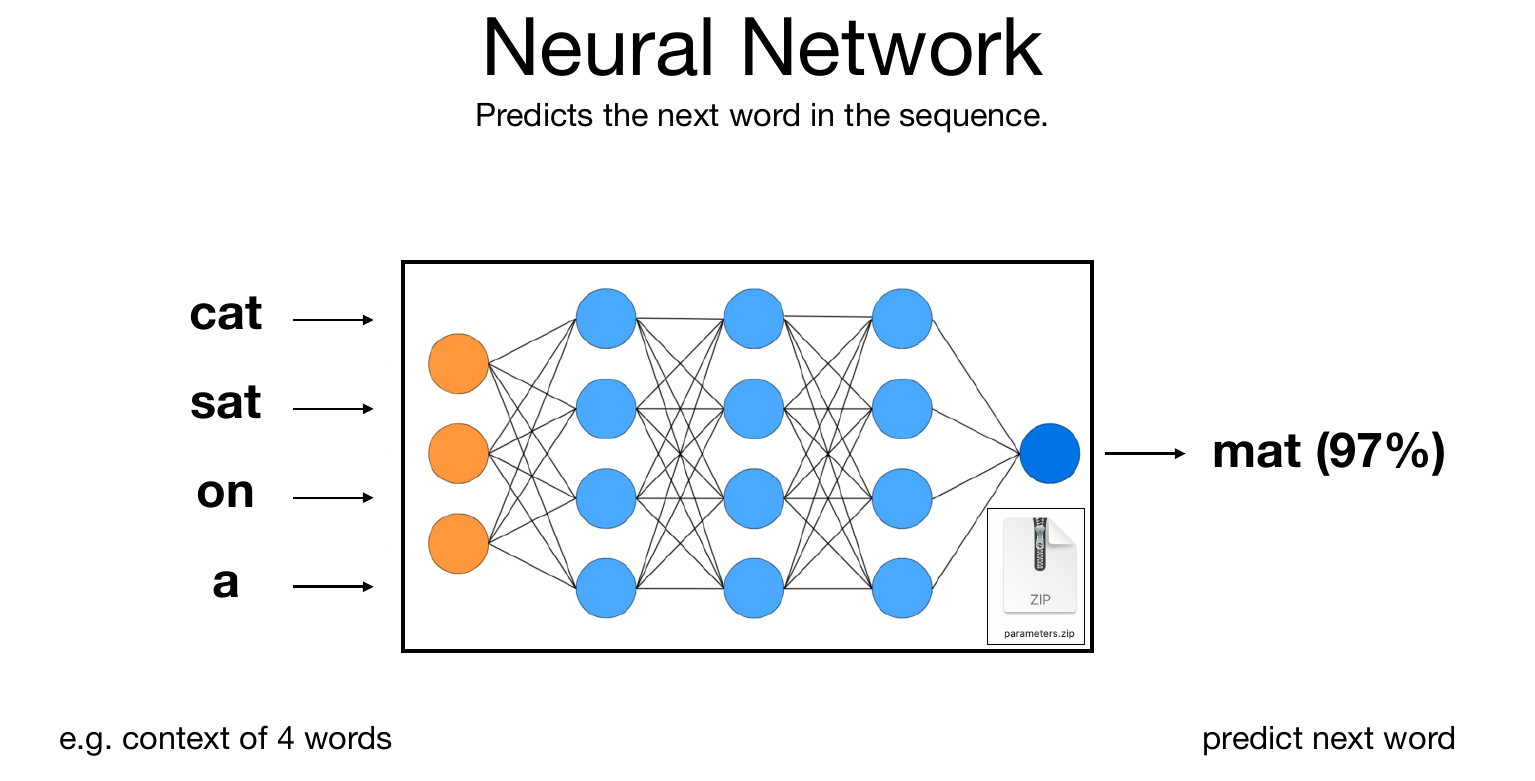
Source Andrej Karpathy: 1hr Talk Intro to Large Language Models
Single Neuron
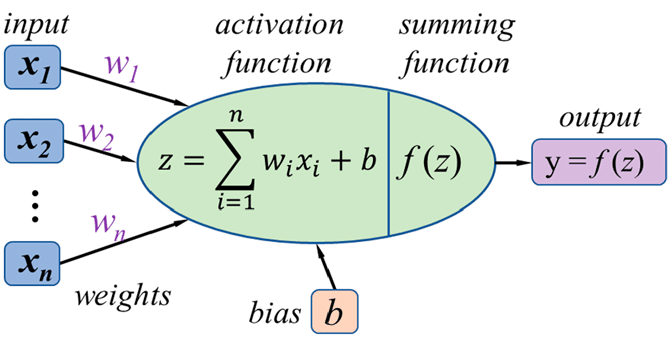
Different activation functions
- Sigmoid, widely used in old NN papers, is not here
- GELU, GPT activation function, is not here also
- More than 20 activation functions exist
- More activation functions are proposed continuously
source: A scalable species-based genetic algorithm for reinforcement learning problems
Neural networks internals
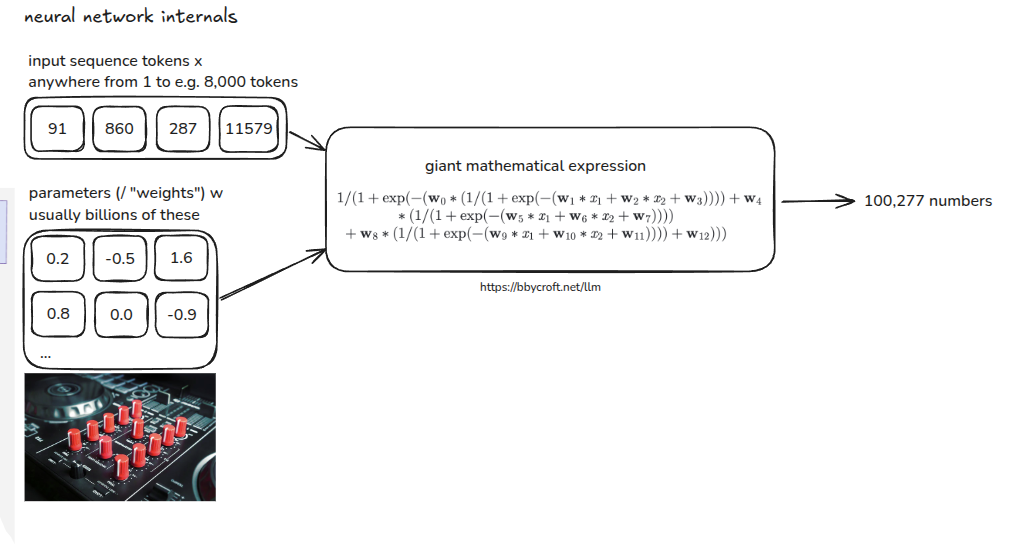
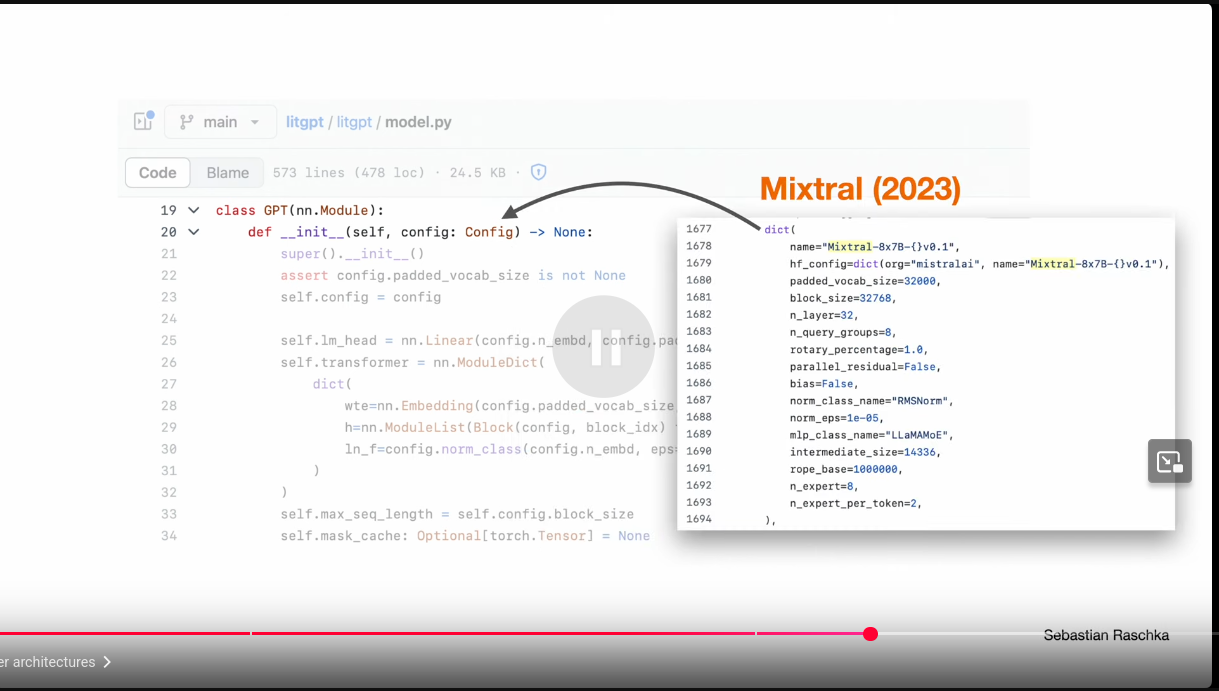
Modern Architectures Derived From GPT
LLM-visualization nano-gpt
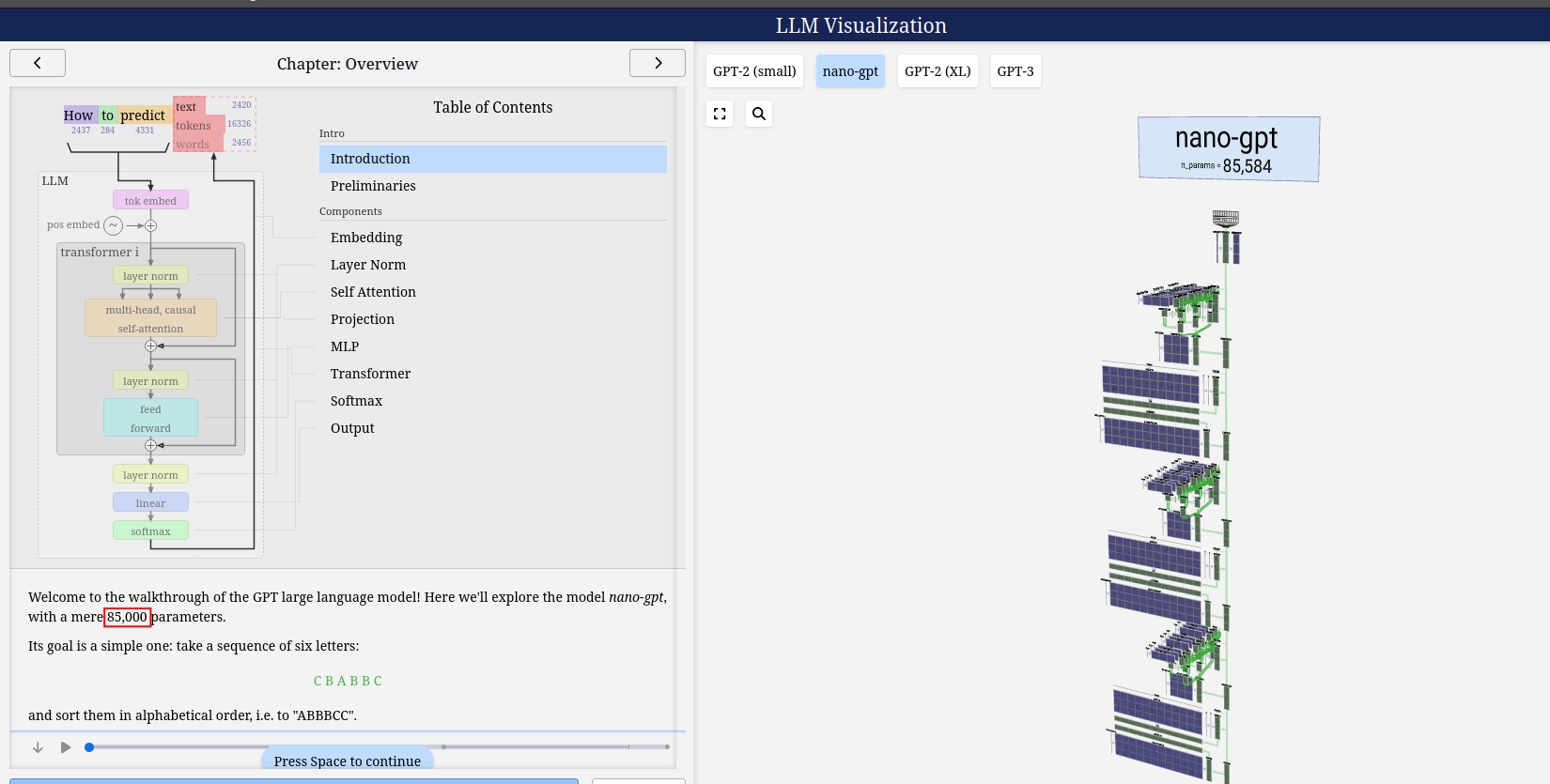
LLM-visualization gpt2
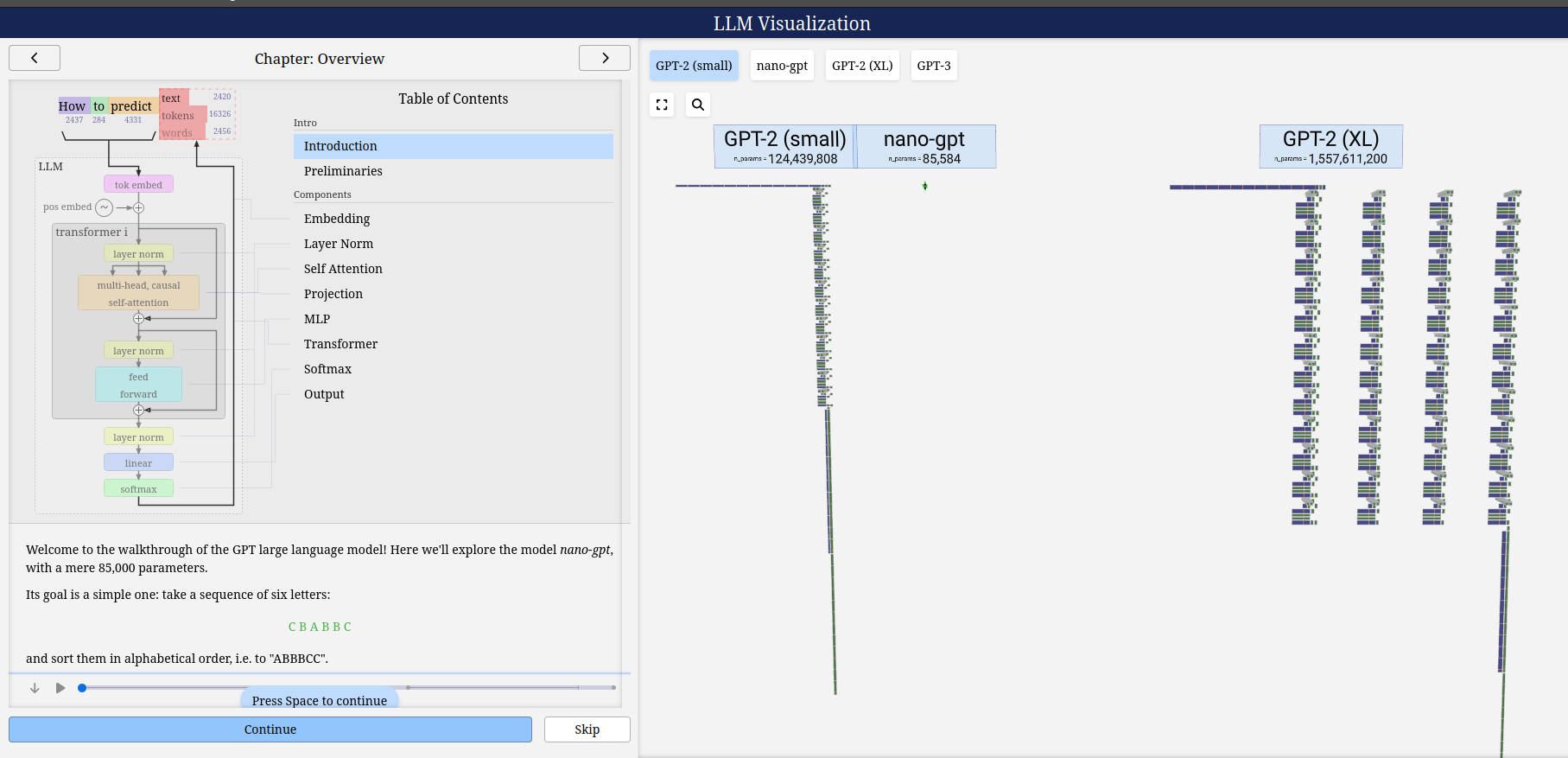
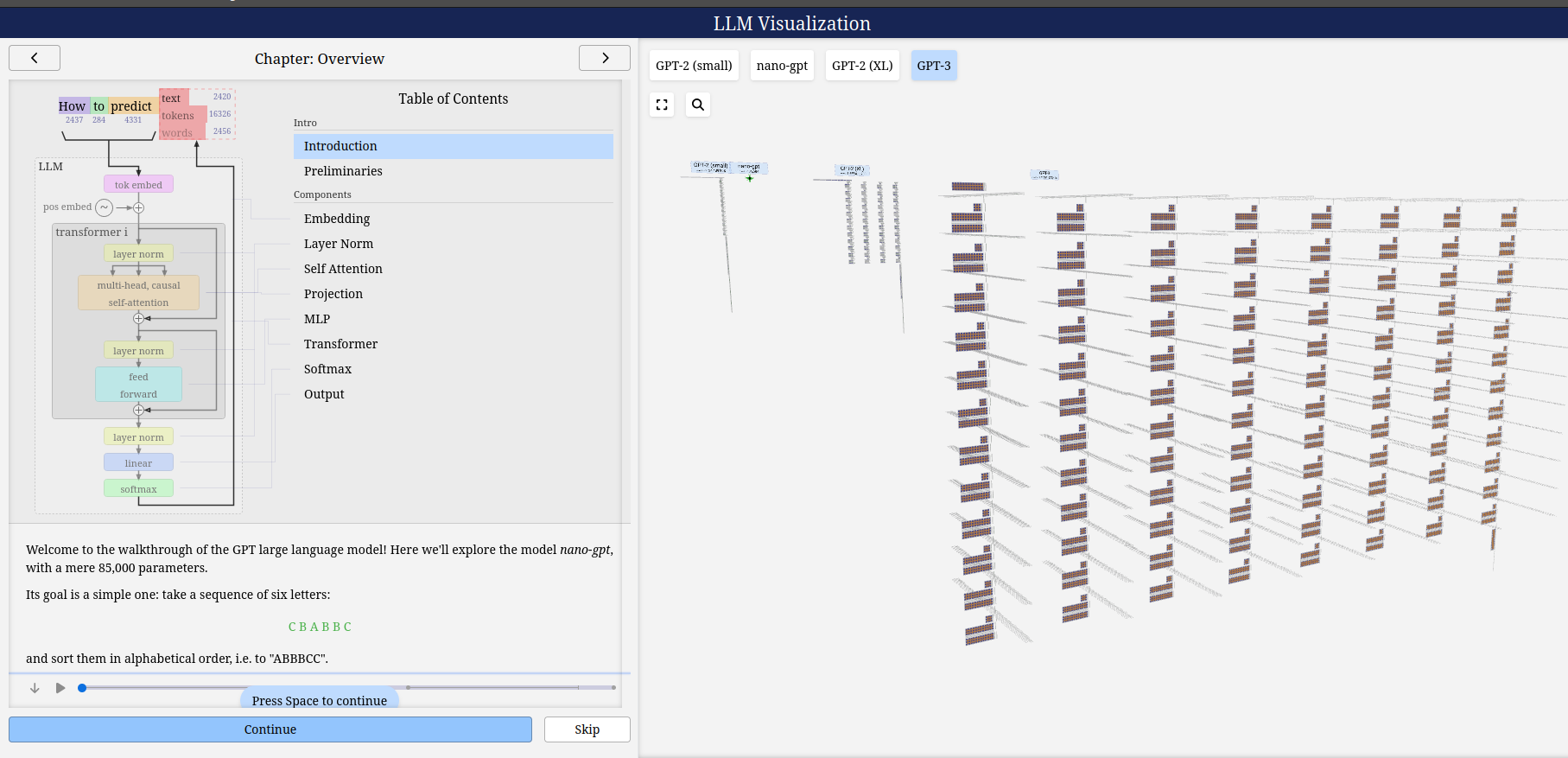
LLM-visualization gpt3
GPT2 sizes
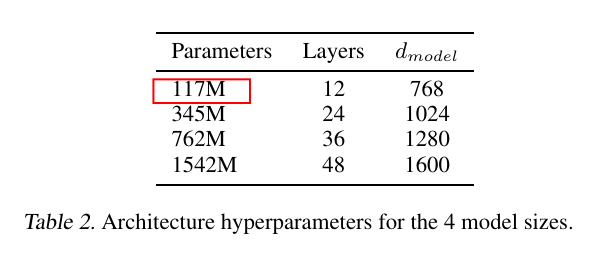
dModel Context Size
Source GPT2 Article: Language Models are Unsupervised Multitask Learners
GPT3 sizes
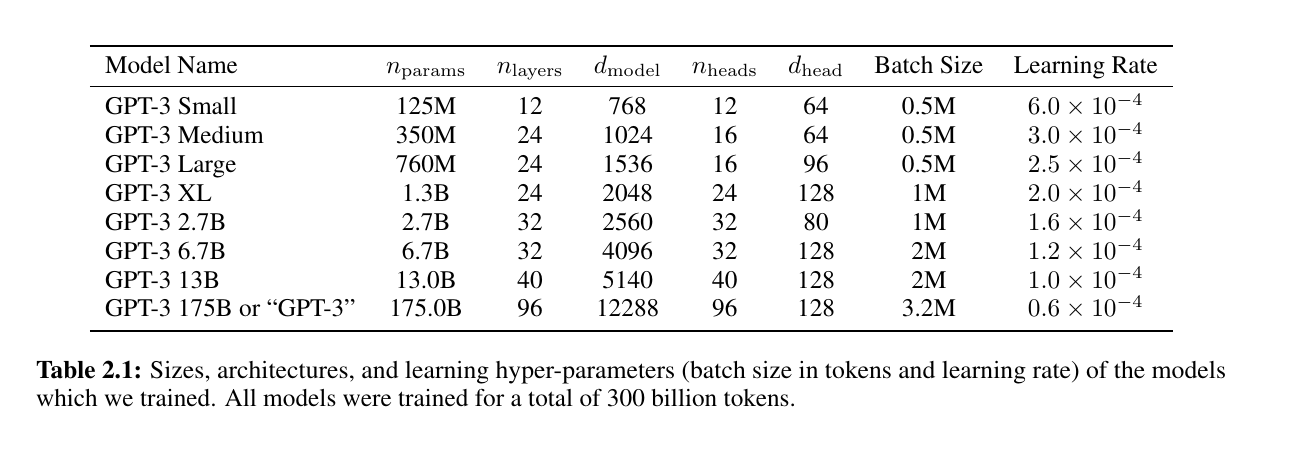
LLM-EvolutionTree
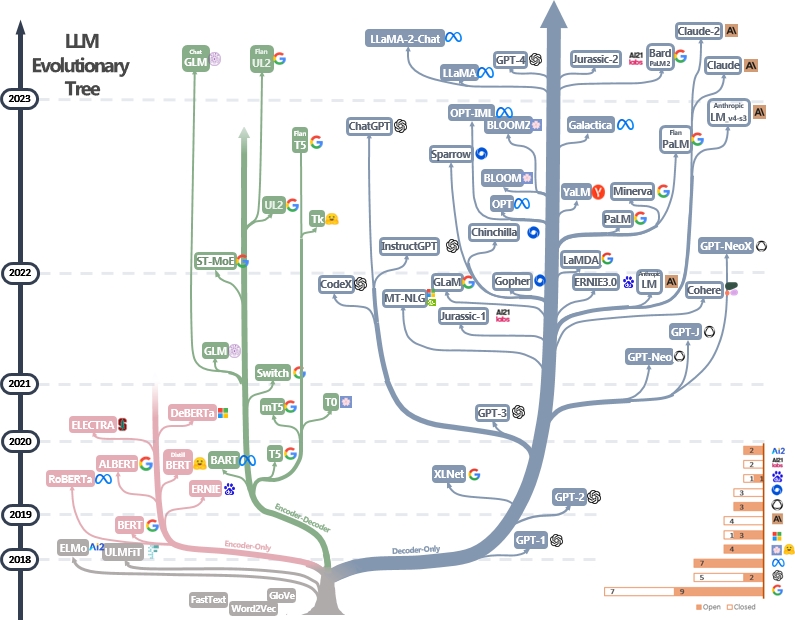
GPT Original architecture
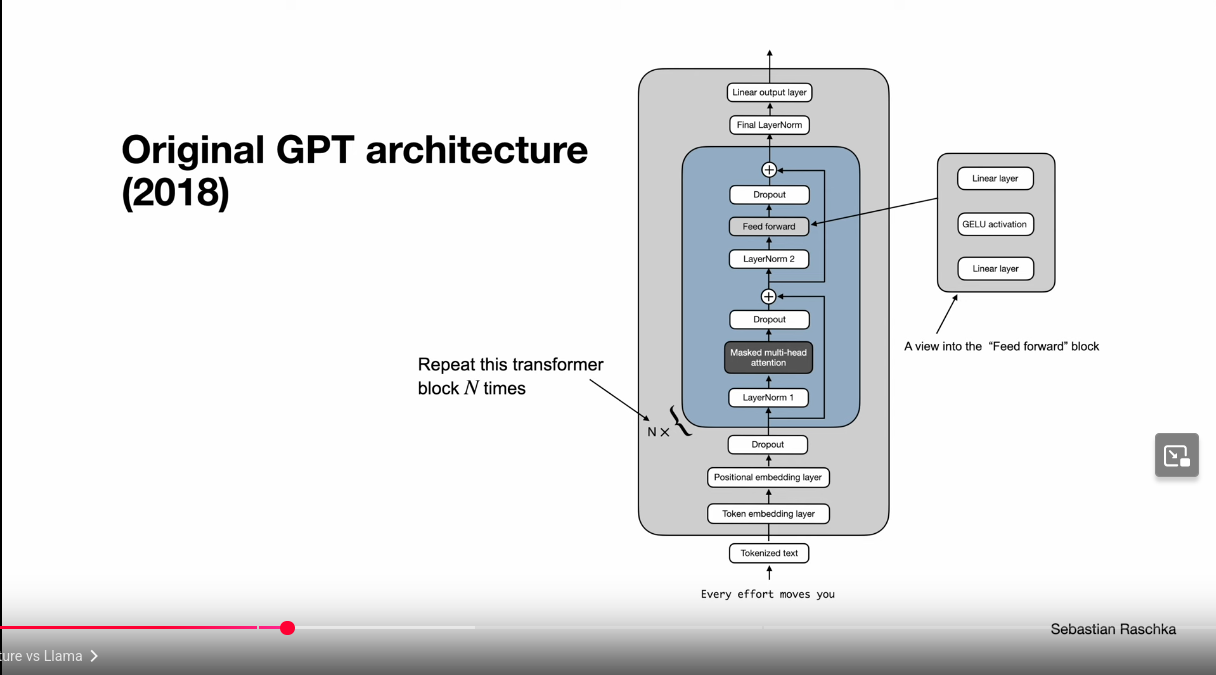
GPT2-architecture
Modern Architectures Derived From GPT
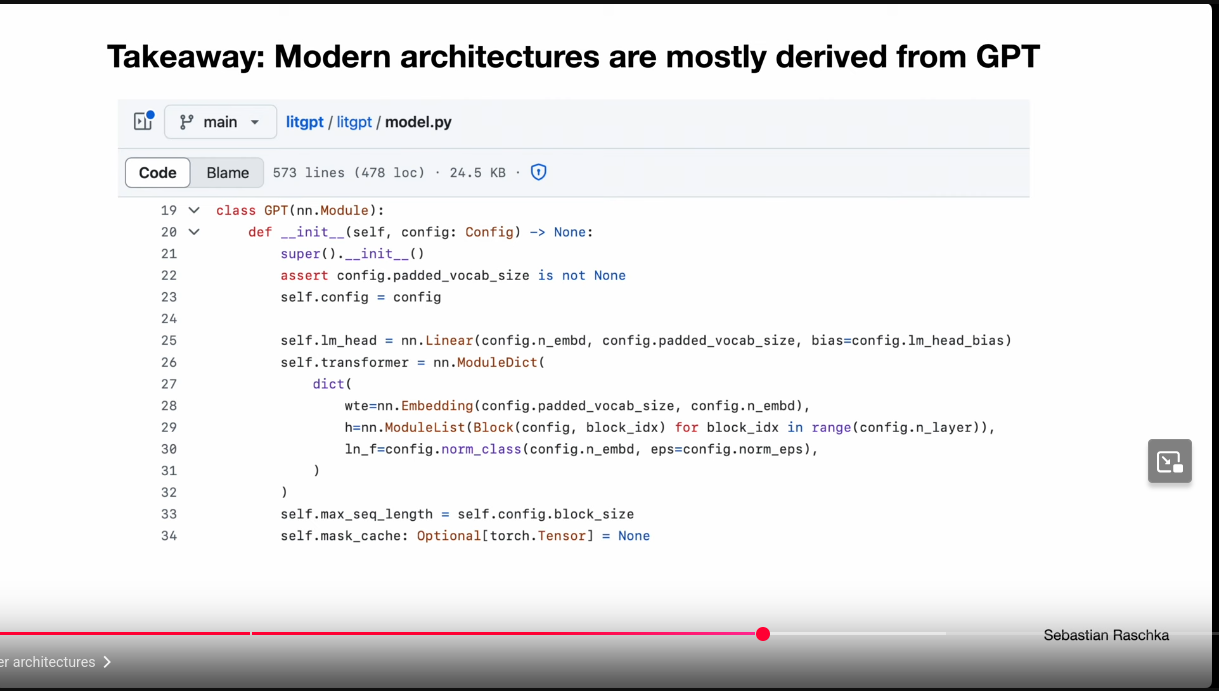
Modern Architectures Derived From GPT: Gemma2
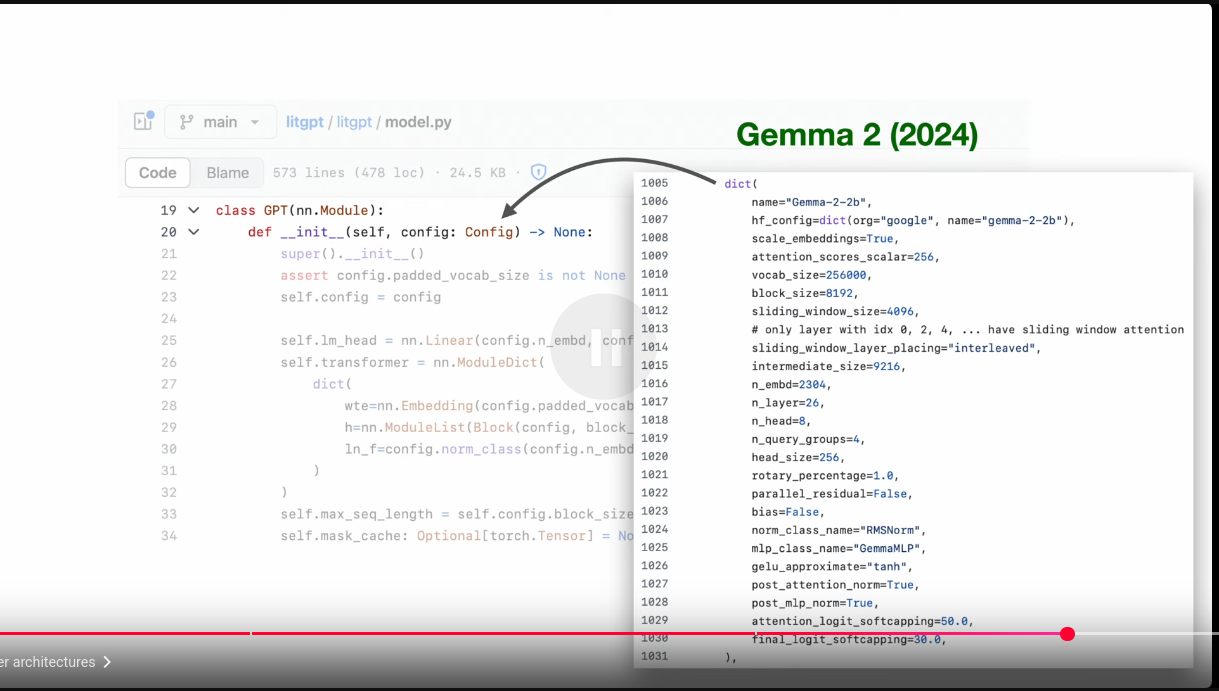
Modern Architectures Derived From GPT: Llama3
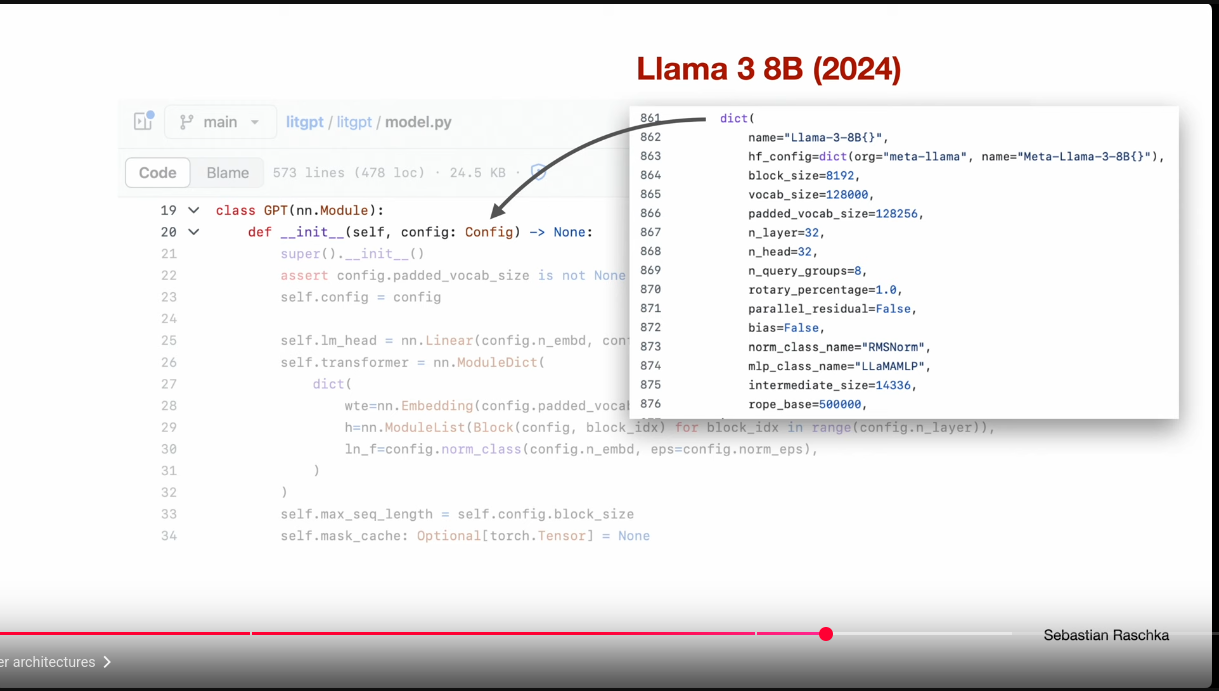
Modern Architectures Derived From GPT: Mixtral
Modern Architectures Derived From GPT: Phi3
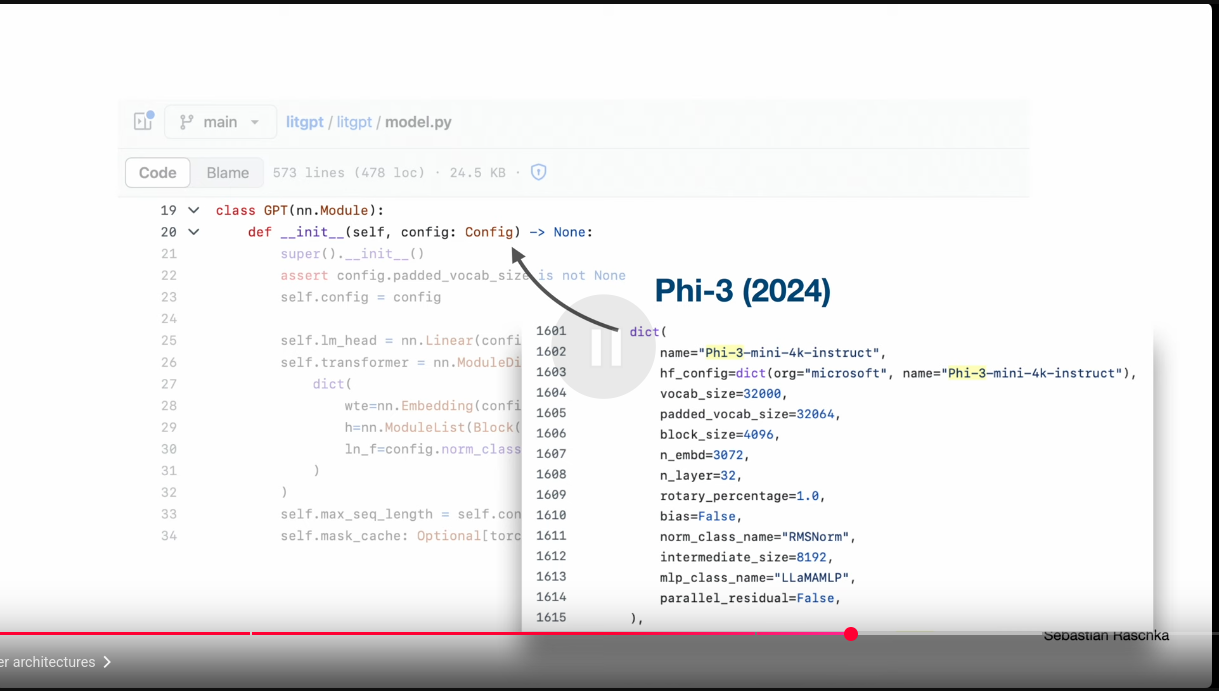
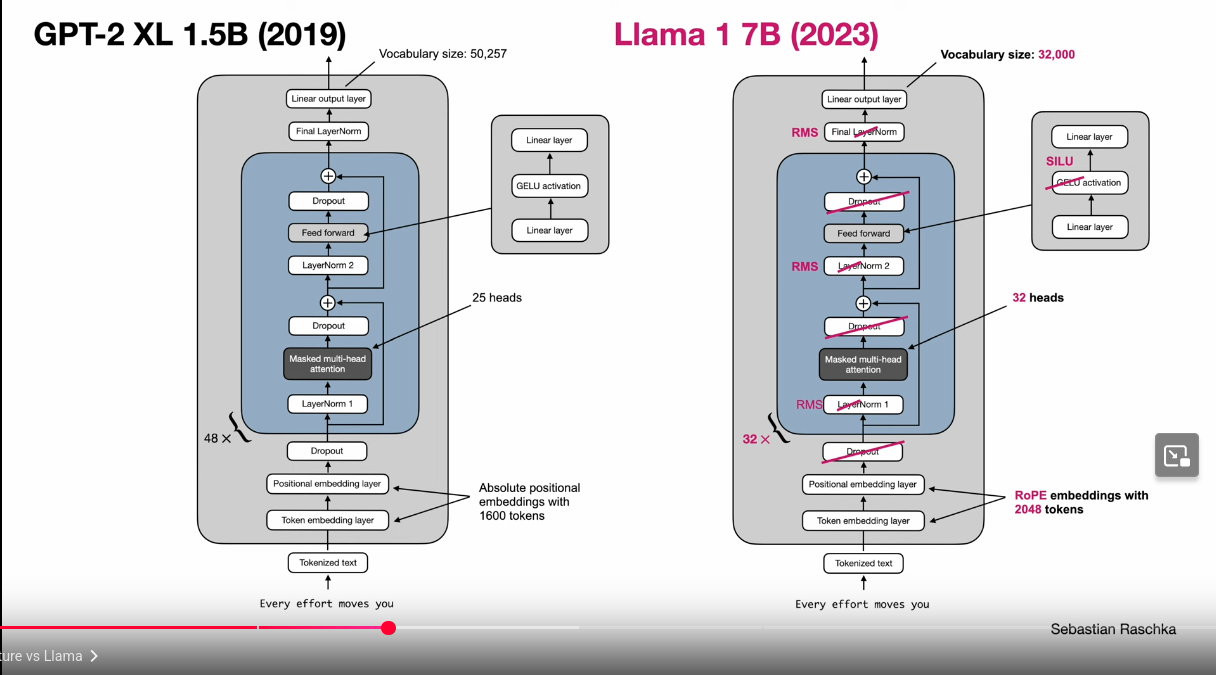
GPT2 vs Llama 1
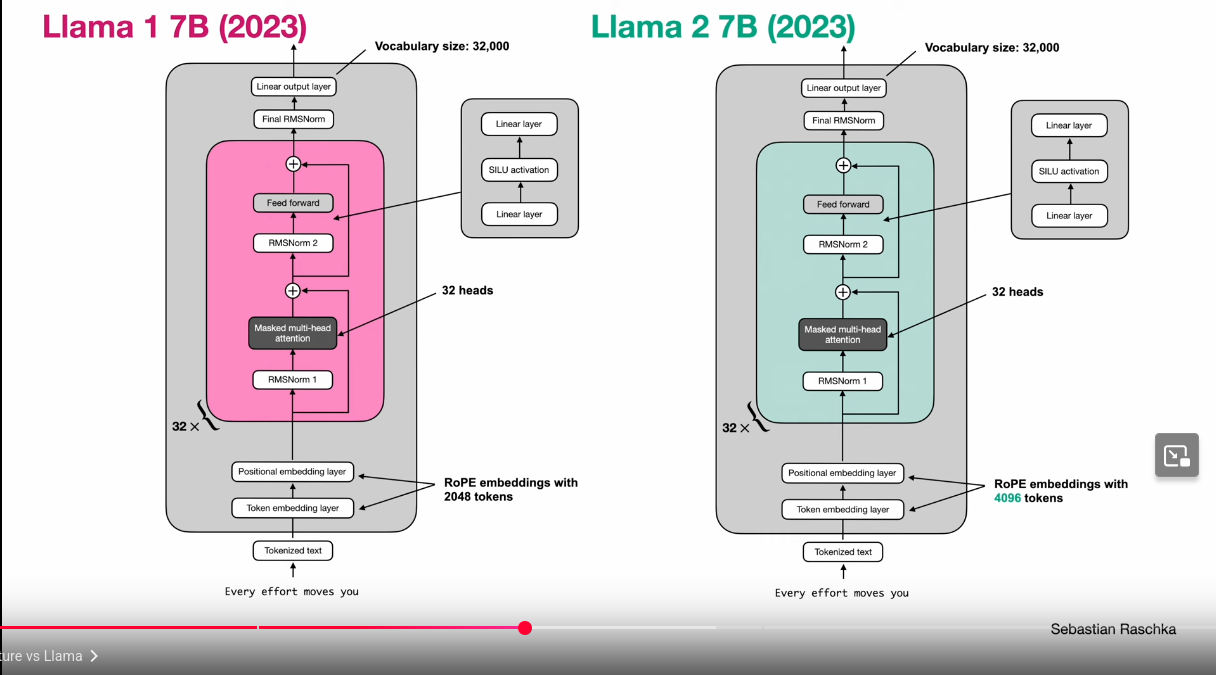
Llama 1 vs Llama 2
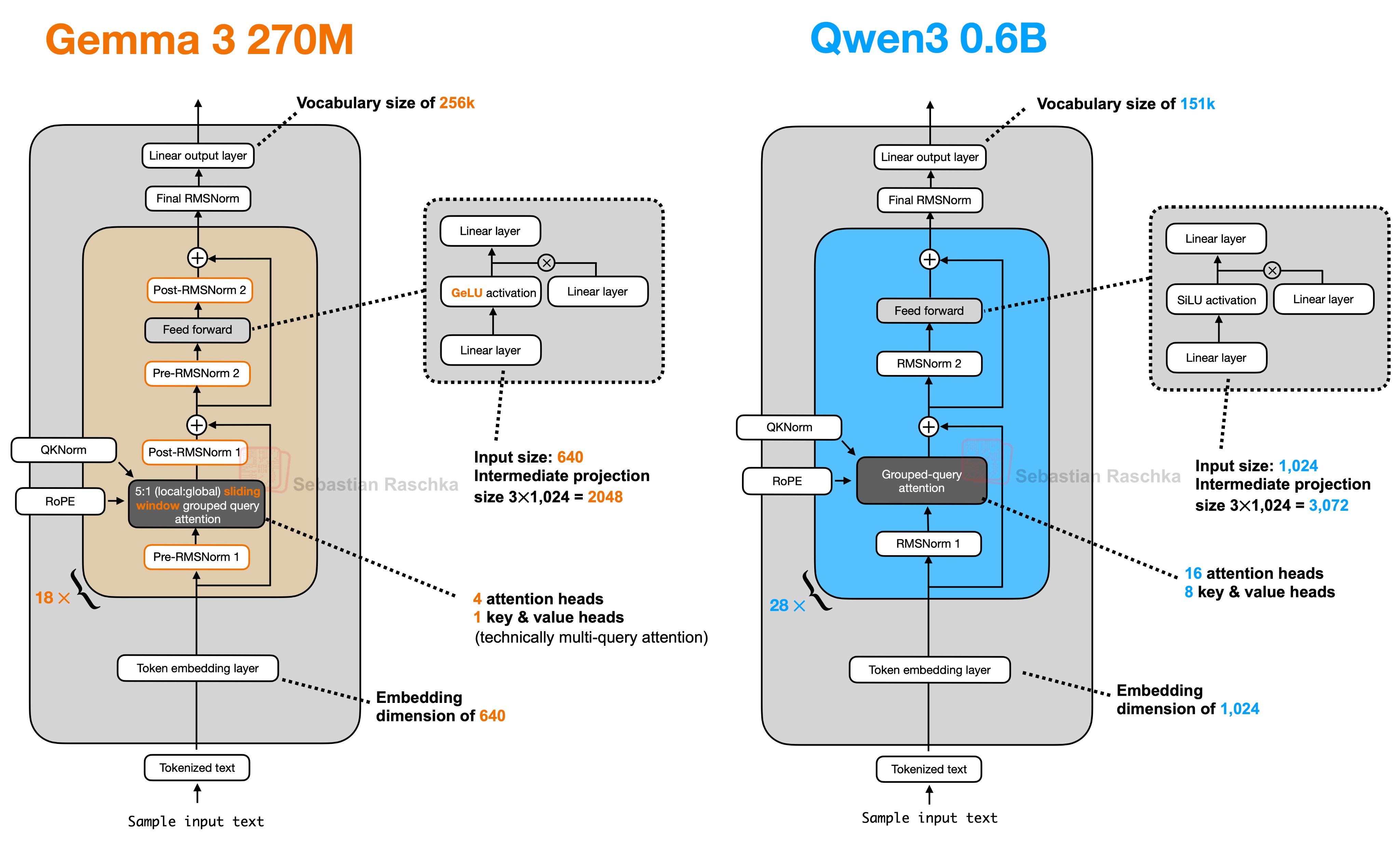
Gemma 3 vs Qwen 3
The Big LLM Architecture Comparison
- Read more in book author’s blog post 2025-07-19
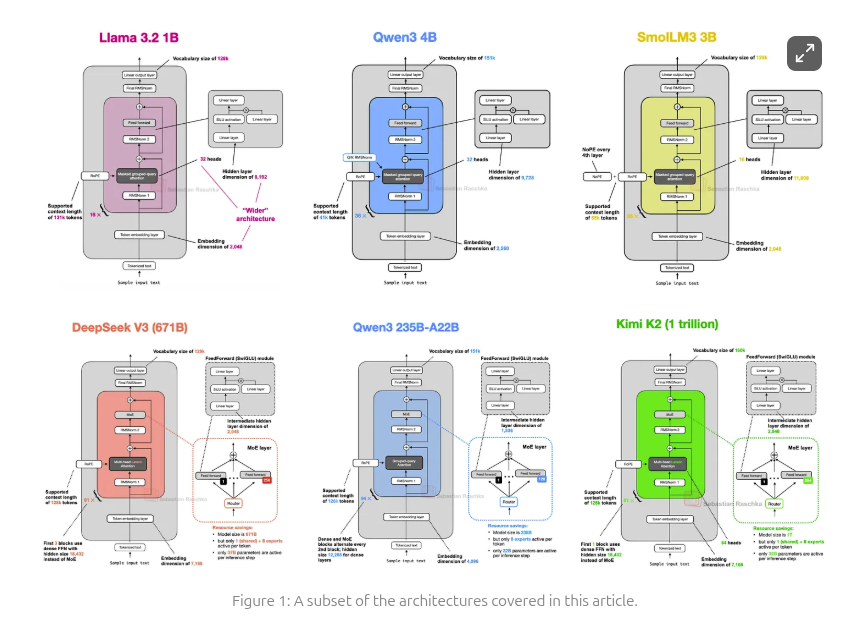
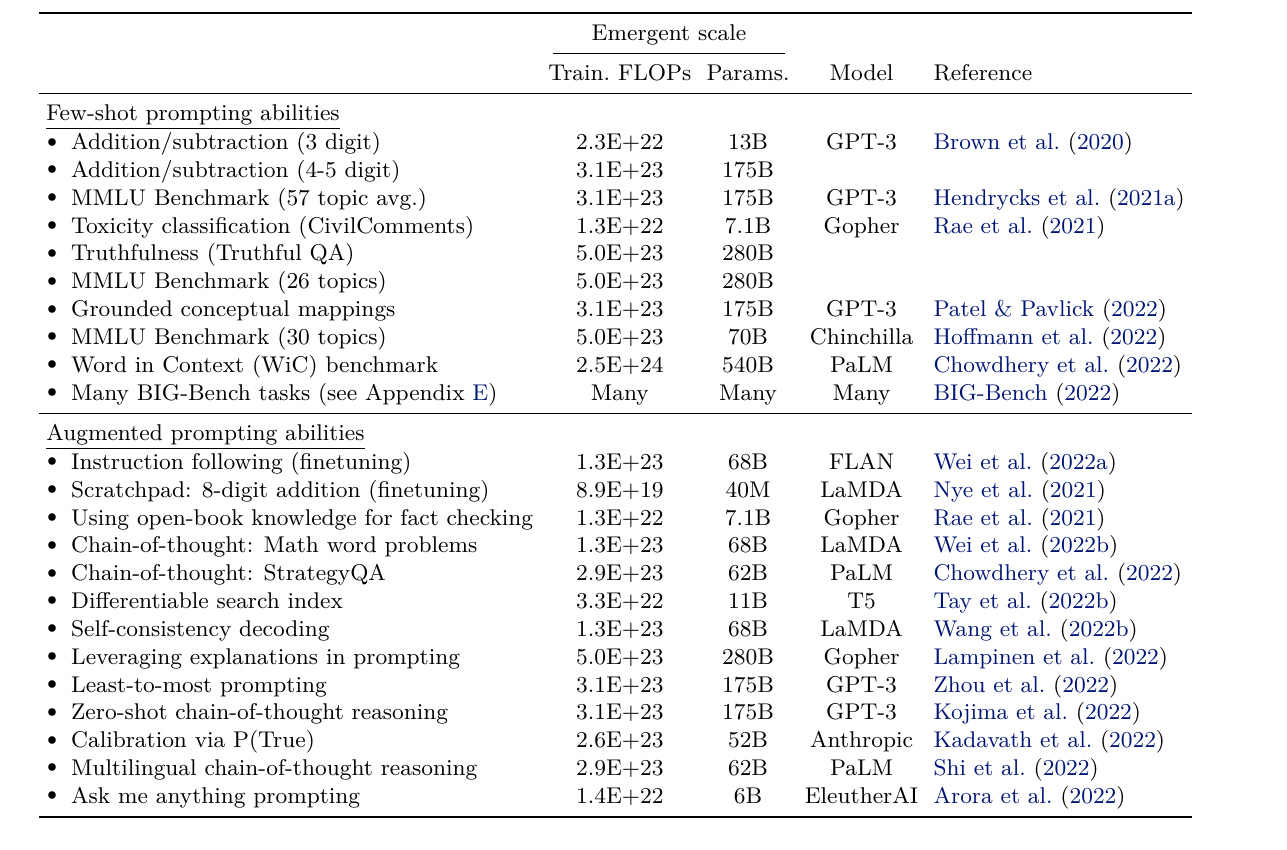
LLM model size vs capabilities
| Model Size (parameters) | Capabilities | Application |
|---|---|---|
| 1B | pattern matching. Basic world knowledge | hotel sentiment analysis |
| 10B | Greater world knowledge. Can follow basic instruction | Simple order chatbot |
| 100B+ | Rich world knowledge. Complex reasoning | Brainstorming partner |
pre-train LLM
Dump language model 1 (Before pre-train)
- When LLM first start training, it randomly generates output.
- Therefore, probability of any word coming is \(\frac{1}{vocabulary size}\)
- GPT2 vocabulary size is 50257
- at the start of the pre-training, we expect to see similar number, 10.82, for loss value
Dump language model 2 (Before pre-train)
flowchart TD
LM["Dump Language Model Vocab Size GPT2"] -->|"Randomly generates output "| P
P["$$p=\frac{1}{50257}$$"]
P --> L1["$$ L = -ln(p) $$"]
L1 --> L2["10.82 "]
LM2["Dump Language Model Vocab Size 100"] -->|"Randomly generates output "| P2
P2("$$p=\frac{1}{100}$$")
P2 --> L21("$$ L = -ln(p) $$")
L21 --> L22("$$ 4.60 $$")
- here, we have to different vocab sizes, 50257 and 100
- correspondingly, we will start with two different losses
Training LLMs Example llama2
Training is like compression of the terabytes of text

Pre-Train step 1 dataset
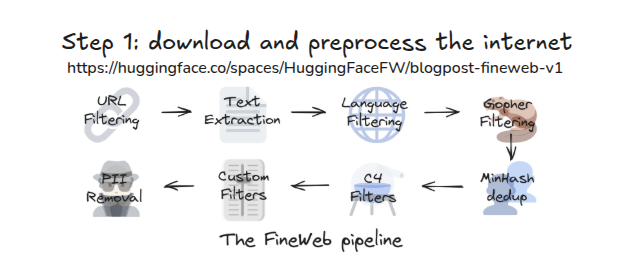
Pre-Train step 2 tokenization

Pre-Train step 3 neural network training
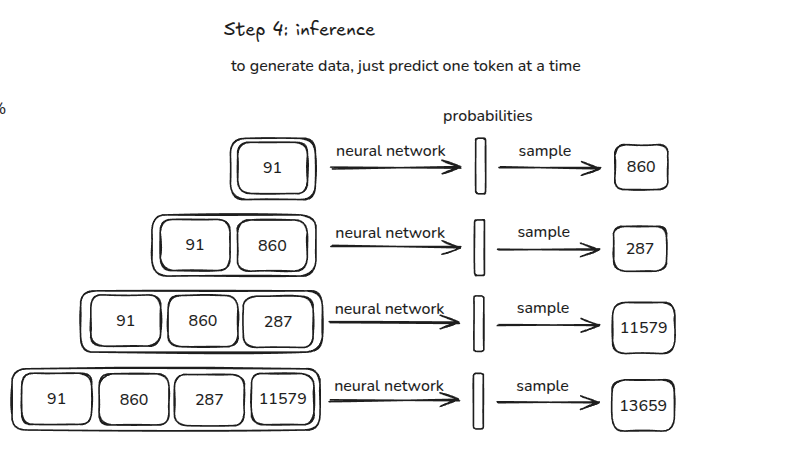
Pre-Train step 4 inference
Pretrain Datasets
When training LLMs, Data quality matters
- diverse data
- harmful speech
- biases
- cleaning data
- deduplication (remove duplicates)
Datasets used to train GPT-3
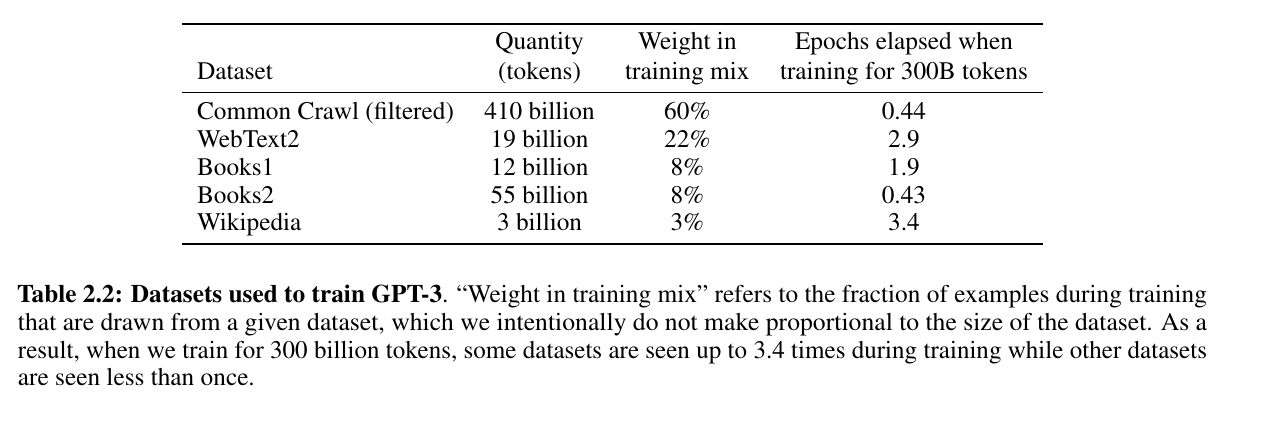
Datasets LLama 2
- Our training corpus includes a new mix of data from publicly available sources, which does not include data from Meta’s products or services.
- We made an effort to remove data from certain sites known to contain a high volume of personal information about private individuals.
- We trained on 2 trillion tokens of data as this provides a good performance–cost trade-off,
- up-sampling the most factual sources in an effort to increase knowledge and dampen hallucinations.
Copyrighted Works Problem
- Meta staff torrented nearly 82TB of pirated books for AI training — court records reveal copyright violations
- OpenAI has been sued by novelists as far back as June 2023 for using their books to train its large language models,
- with The New York Times following suit in December. - Nvidia has also been on the receiving end of a lawsuit filed by writers for using 196,640 books to train its NeMo model, which has since been taken down.
- A former Nvidia employee blew the whistle on the company in August of last year, saying that it scraped more than 426 thousand hours of videos daily for use in AI training.
- More recently, OpenAI is investigating if DeepSeek illegally obtained data from ChatGPT, which just shows how ironic things can get.
- source
Using Copyrighted Works in LLMs according to www.copyright.com
LLMs use massive amounts of textual works—many of which are protected by copyright.
To do this, LLMs make copies of the works they rely on, which involves copyright in several ways, such as:
Using copyright-protected material in the training datasets of LLMs without permission can result in the creation of unauthorized copies: copies generated during the training process and copies in the form of representations of the training data embedded within the LLM after training. This creates potential copyright liability.
Outputs—the material generated by AI systems like LLMs—may create copyright liability if they are the same or too similar to one of the copyrighted works used as an input unless there is an appropriate copyright exception or limitation.
Datasets
- Common crawl (Over 300 billion pages spanning 18 years) with variations
- Star coder almost 800 GB Code examples
- fine web 18.5T tokens
- Arxiv (Academic papers)
Datasets Hugging face FineWeb
The 🍷 FineWeb dataset consists of more than 18.5T tokens (originally 15T tokens) of cleaned and deduplicated english web data from CommonCrawl.
The data processing pipeline is optimized for LLM performance and ran on the 🏭 datatrove library, our large scale data processing library.
https://huggingface.co/datasets/HuggingFaceFW/fineweb
Pre training different models

source Sebastian Raschka: LLMs: A Journey Through Time and Architecture
Pre-training costs of different models
| Model | Release year | Reported training GPU-hours | Reported GPU fleet / type | Reported training time | Estimated compute cost (USD) | Notes |
|---|---|---|---|---|---|---|
| GPT-2 (1.5B) — original | 2019 | Not publicly disclosed | Not publicly disclosed | N/A | OpenAI did not publish training time or cost. | |
| GPT-2 (repro, modern hardware) | 2024 | ≈192 GPU-hrs (8×H100 for ~24h) | 8× H100 (80GB) | ≈24 hours | ≈$600–$800 | Community reproduction. not the 2019 original run. |
| GPT-3 (175B) | 2020 | V100-era | compute ≈3.14e23 FLOPs | “Multiple weeks” (reports) | ≈$0.5M–$4.6M (est.) Cost varies widely by assumptions. compute from paper. | |
| GPT-4 | 2023 | Undisclosed (estimates: ~25k A100s) | Est. ~90–100 days (unofficial) | > $100M (various estimates) | OpenAI hasn’t disclosed. Figures are outside estimates. | |
| Llama 2 (7B–70B) | 2023 | ≈3.3M A100-80GB GPU-hrs | NVIDIA A100 80GB | Depends on cluster size | ≈$5M–$8M (at $1.5–$2.5/GPU-hr) | From Meta paper. cost uses common rental ranges. |
| Llama 3.1 (405B) | 2024 | ≈30.84M H100 GPU-hrs | H100 | ~24k GPUs over ~54 days (reports) | ≈54 days (reported) | ≈$62M–$93M (at $2–$3/GPU-hr). GPU-hrs from engineering report. time from news coverage. |
| Llama 4 Scout (17B) | 2025 | ≈7.38M H100-80GB GPU-hrs | H100 80GB | Not disclosed | ≈$15M–$22M (at $2–$3/GPU-hr) | From NVIDIA/Meta model card summary. |
| Claude 3.7 Sonnet | 2025 | Undisclosed (<1e26 FLOPs claim) | Not disclosed | “Few tens of millions” (company guidance via press) | Anthropic hasn’t published full training details. | |
| Grok 2 | 2024 | ≈20,000 H100 (per Musk) | Not disclosed | N/A (hours unknown) | GPU count stated publicly. no official hours. | |
| Grok 3 | 2025 | Claims: 100k–200k H100s | Not disclosed | N/A (claims vary) | Numbers are public claims/reports. not independently verified. | |
| DeepSeek-V3 | 2024 | ≈2.788M H800 GPU-hrs | NVIDIA H800 | Depends on cluster size | ≈$5.6M (@ $2/GPU-hr) | From DeepSeek paper and analyses. |
Sam-Altman-1million-GPU
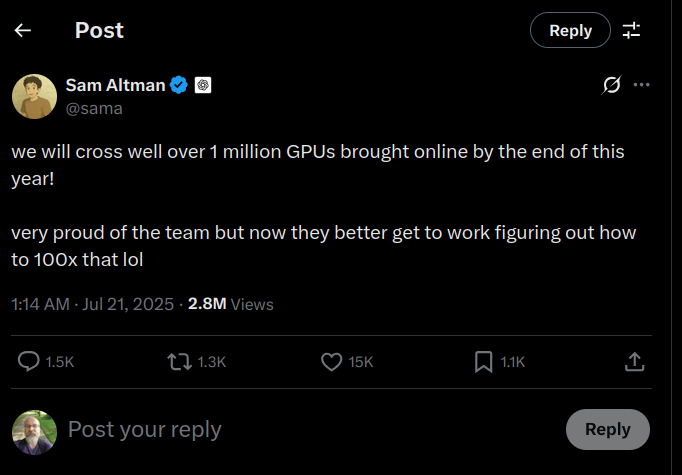
Pre-train speed up
pre-training speed up
- We will not cover this topic
- GPU parallelization
- learning rates
- optimizers
- quantization (32 bit –> 16 bit)
- and others, active research
Parallelization
- Data parallelization
- Tensor parallelization (split matrix multiplication to multiple GPUs)
- Pipeline parallelization (transformer layers to multiple GPUs)
- Model parallelization
pre-training tricks examples
We will not cover this topic
Let’s make it fast. GPUs, mixed precision, 1000ms
Tensor Cores, timing the code, TF32 precision, 333ms
float16, gradient scalers, bfloat16, 300ms
torch.compile, Python overhead, kernel fusion, 130ms
flash attention, 96ms
nice/ugly numbers. vocab size 50257 → 50304, 93ms
hyperpamaters, AdamW, gradient clipping
learning rate scheduler: warmup + cosine decay
batch size schedule, weight decay, FusedAdamW, 90ms
After Pretrain
next word prediction becomes powerful
neural network dreams documents
Psychology of base model

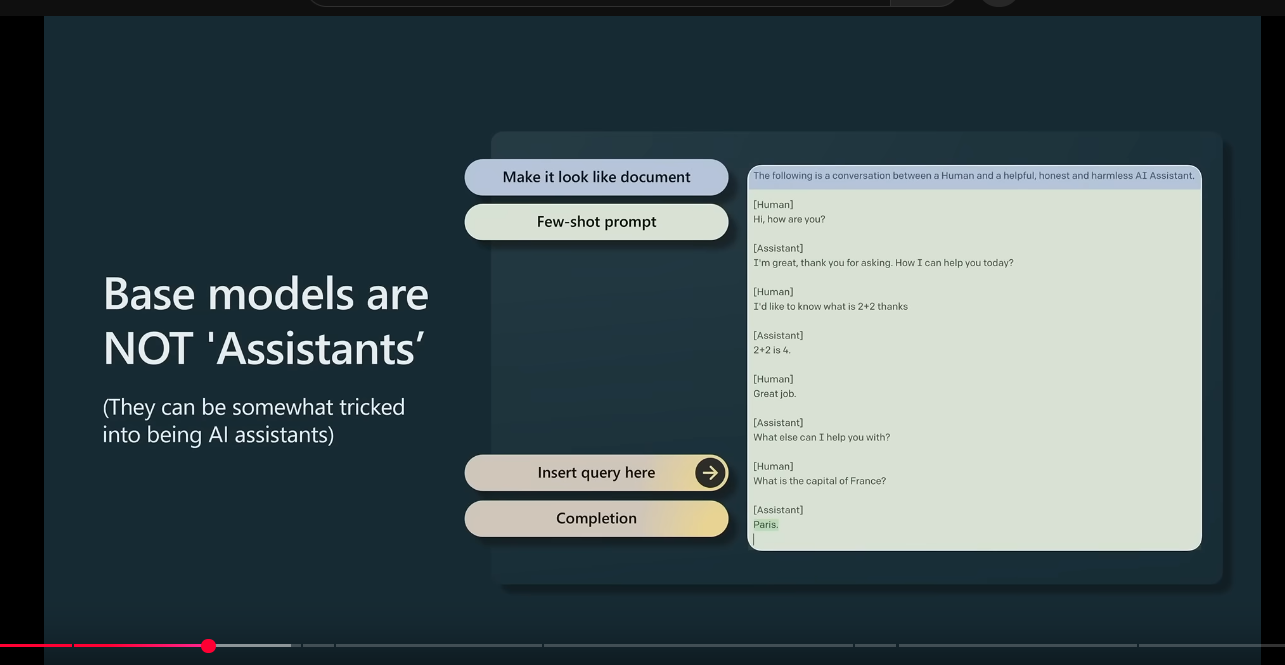
base models are not assistants 1

base models are not assistants 2
knowledge of self

human text generation vs llm text generation 1

human text generation vs llm text generation 2

Swiss cheese model of LLM

Hallucinations

Models can’t count

how to train your ChatGPT
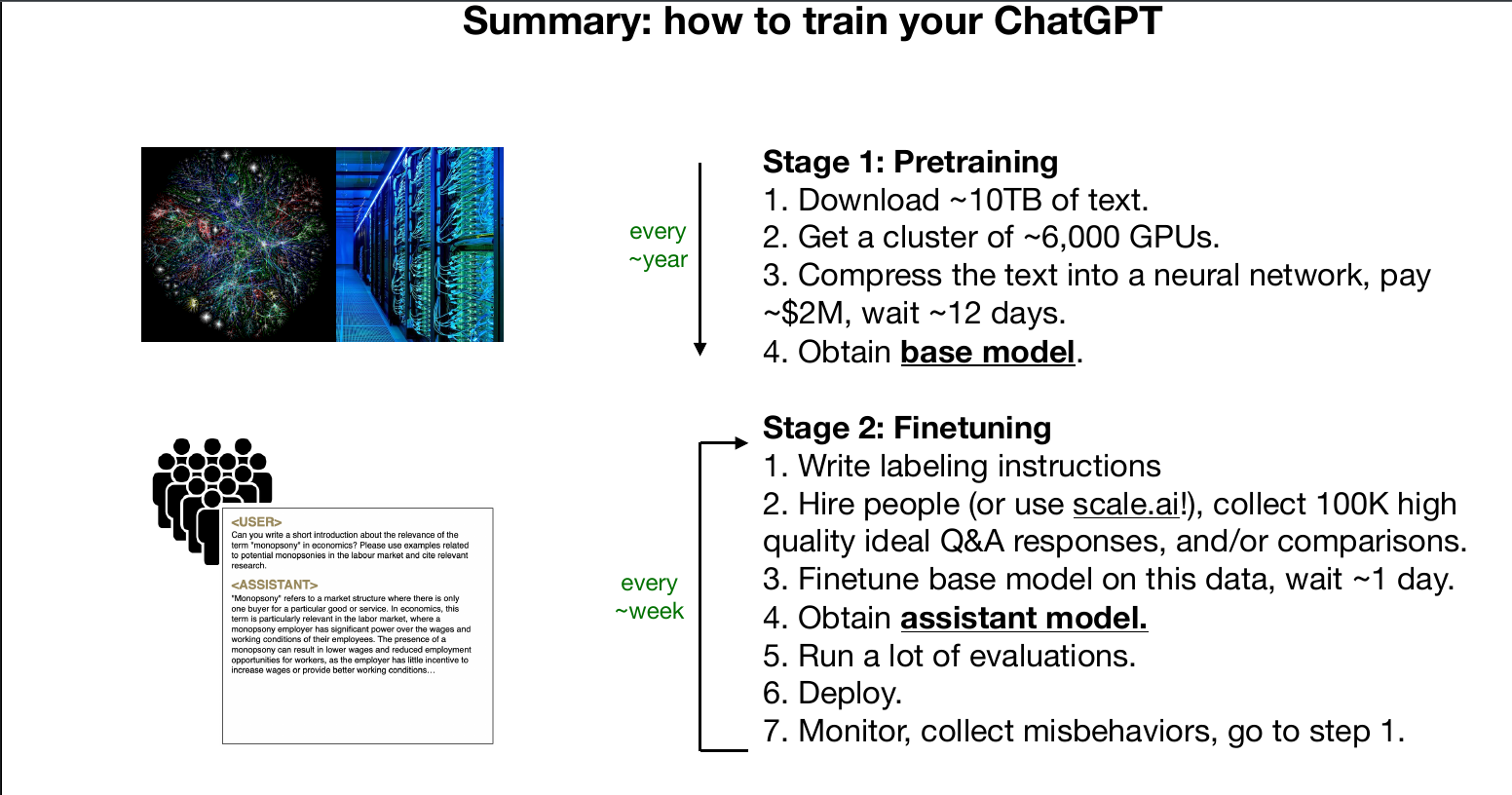
Andrej Karpathy 1hr Talk Intro to Large Language Models
Supervised Fine Tuning (Instruct GPT)

training the assistant

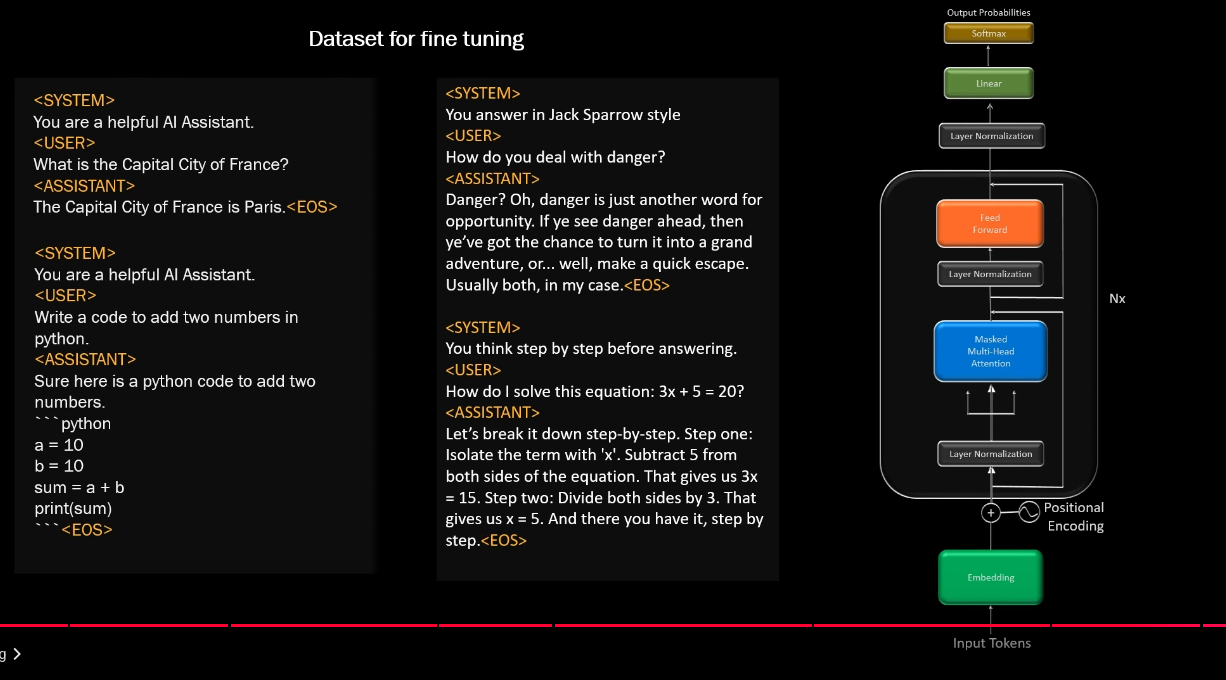
datasets conversation 1

datasets conversation 2

datasets conversation 3
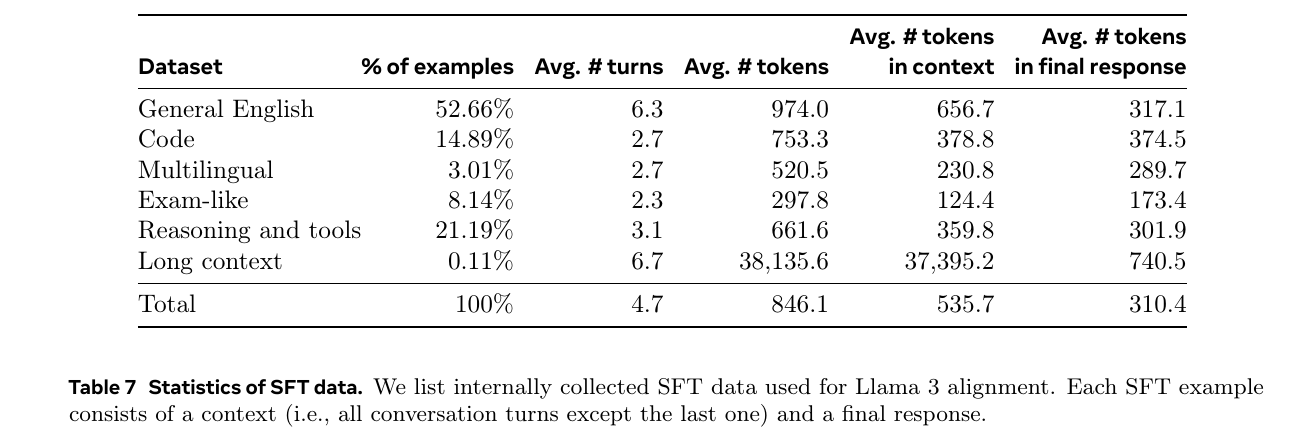
LLama3 SFT datasets
Deepseek may have used OpenAI ChatGPT output
- OpenAI says it has proof DeepSeek used its technology to develop its AI model
- OpenAI Hit With Wave of Mockery for Crying That Someone Stole Its Work Without Permission to Build a Competing Product
- “You can’t steal from us! We stole it fair and square!”
Google and OpenAI blames China for distillation attempts
https://x.com/AnthropicAI/status/2025997928242811253
We’ve identified industrial-scale distillation attacks on our models by DeepSeek, Moonshot AI, and MiniMax.
These labs created over 24,000 fraudulent accounts and generated over 16 million exchanges with Claude, extracting its capabilities to train and improve their own models.SFT after fine tuning you have assistant

After fine tuning Emergent behavior
Course contents for LLM
LLM Arena
LLM Arena overview
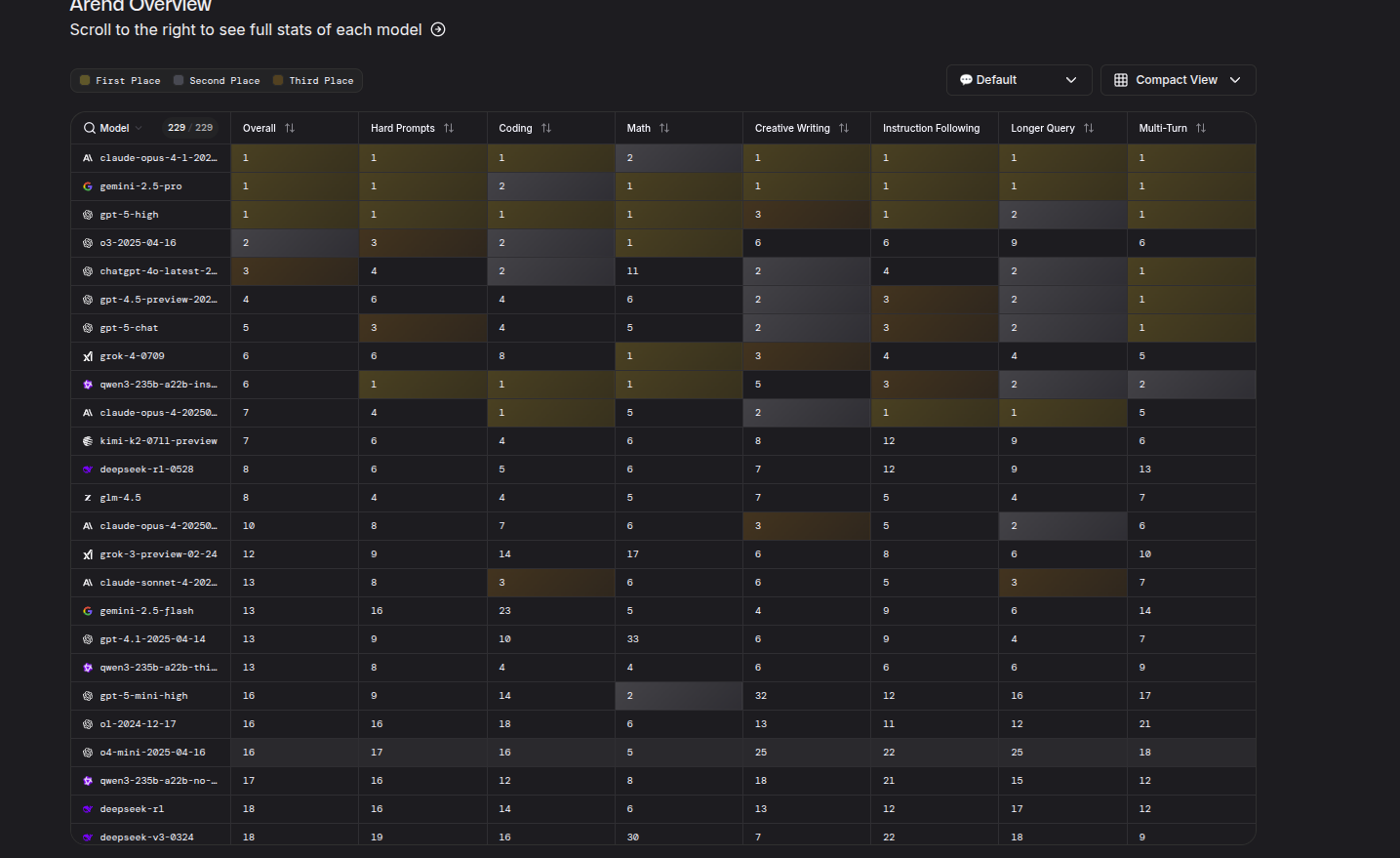
LLM Arena copilot
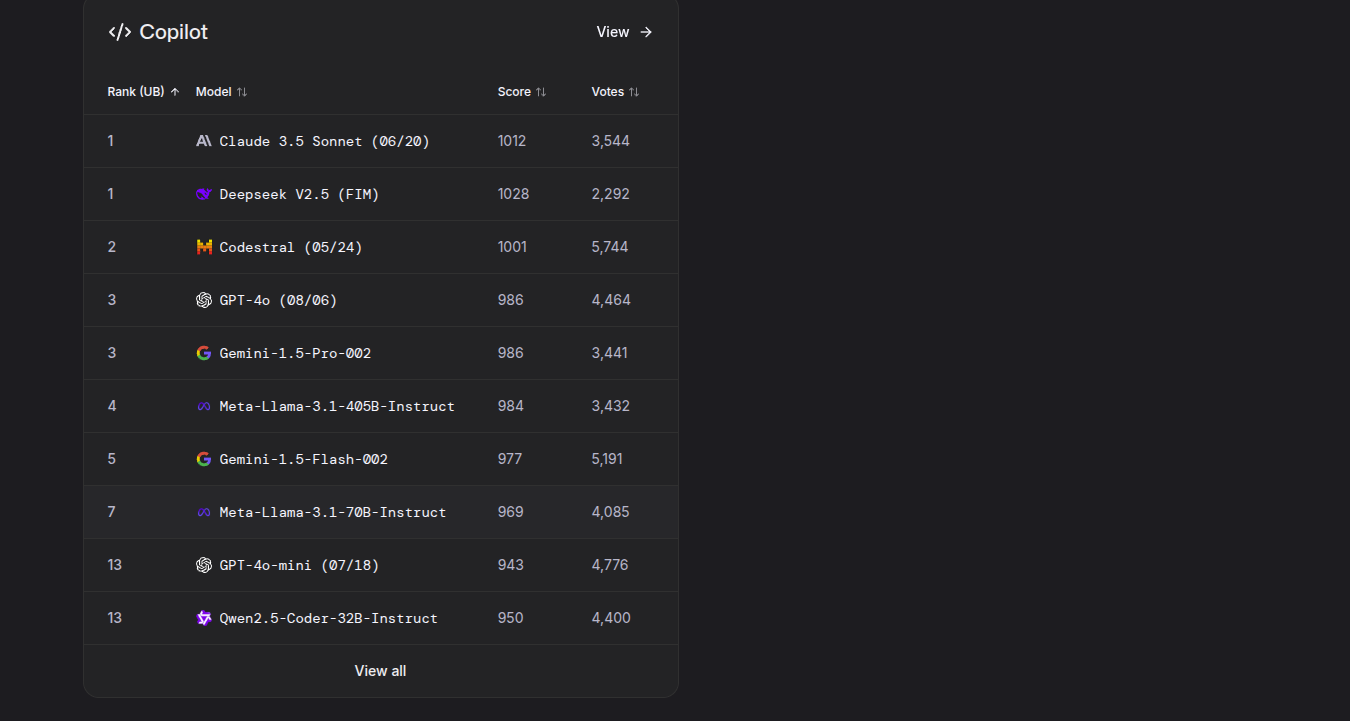
LLM Arena text-to-video and image-to-video
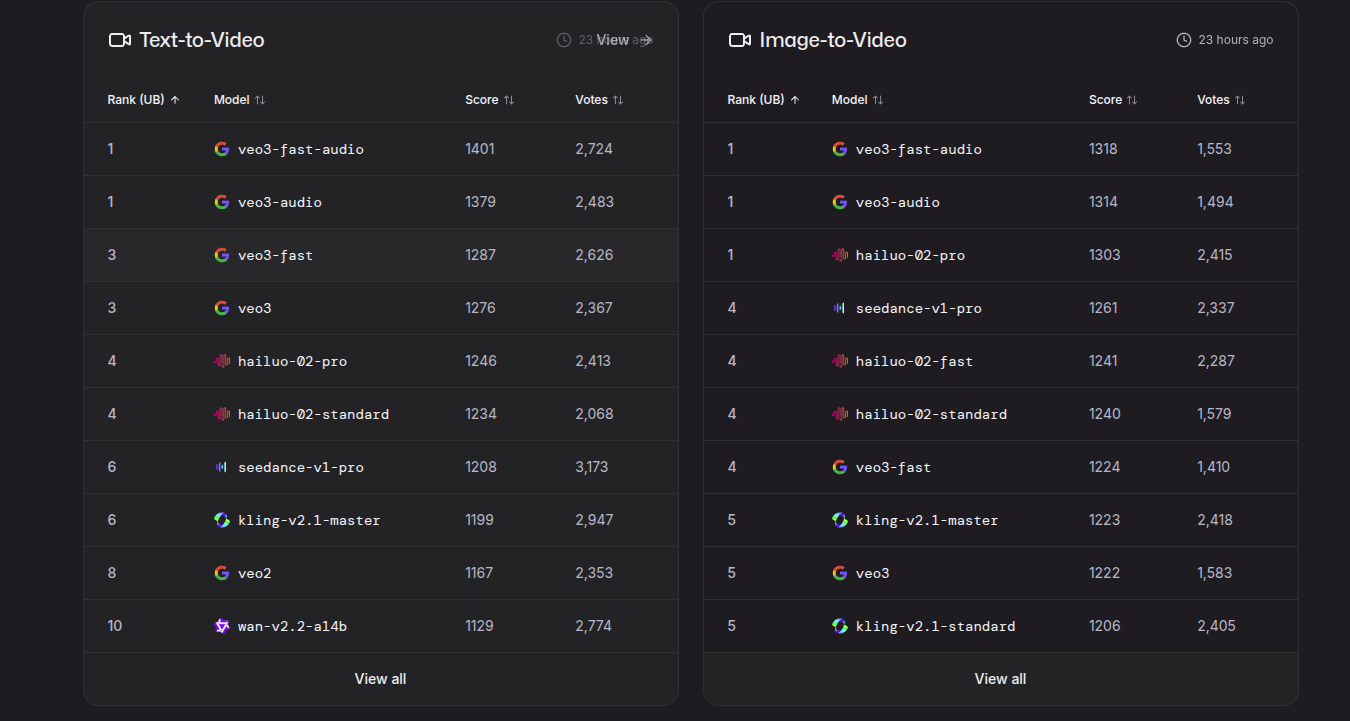
LLM Arena image edit and search
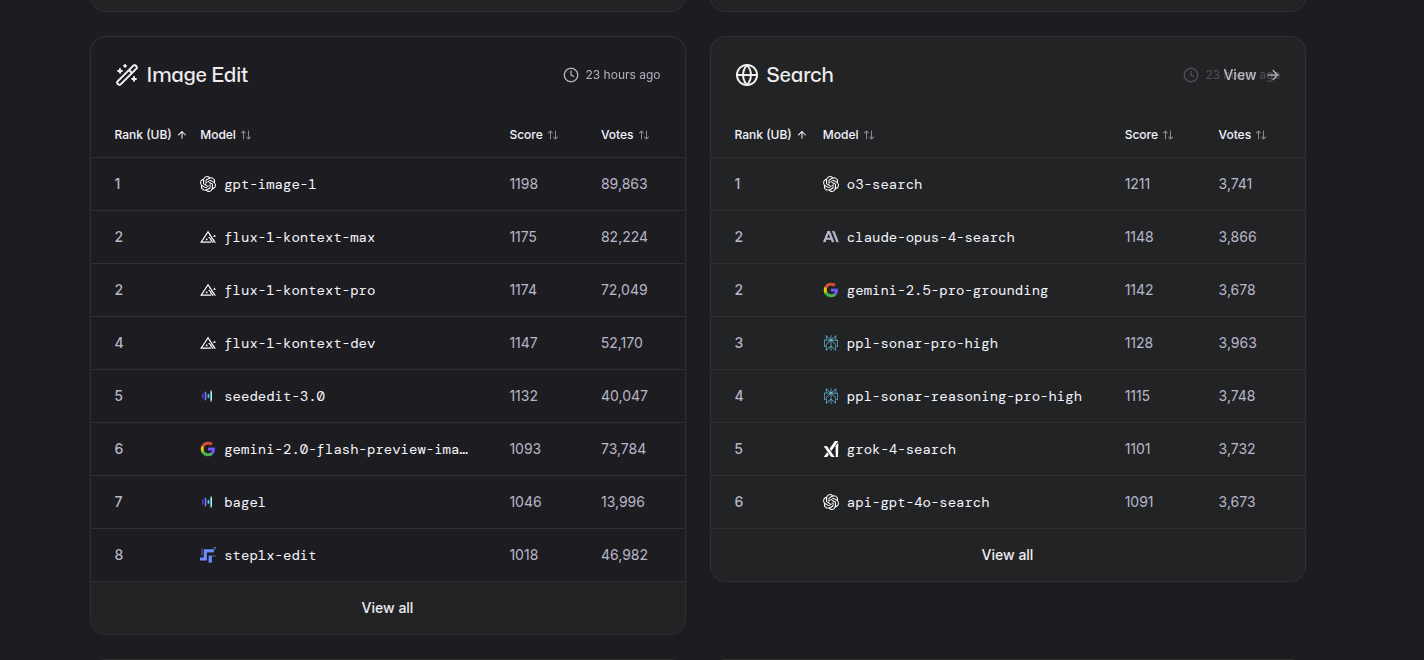
LLM Arena vision and text-to-image
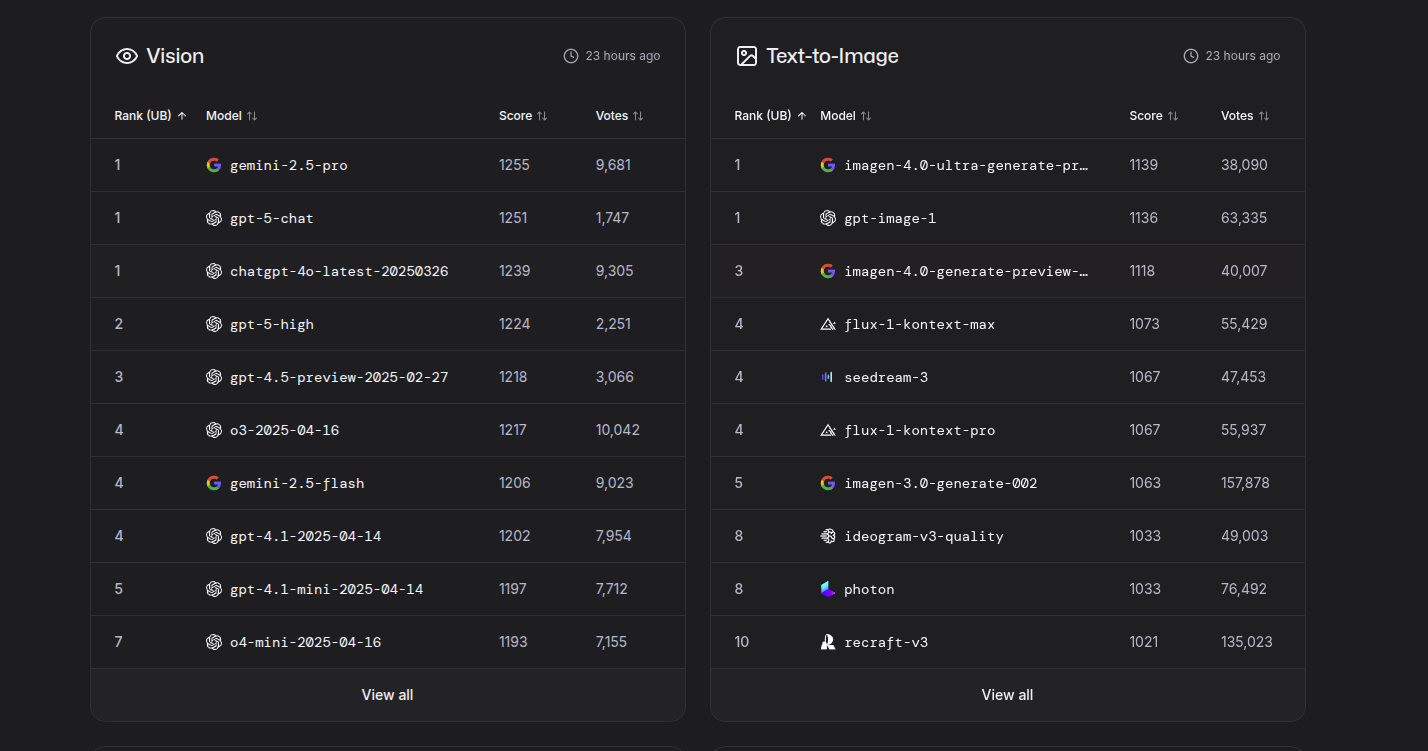
LLM Arena text and webdev
Foundational/base models
Foundational/base models: ollama models popular
Foundational/base models: ollama models instruct
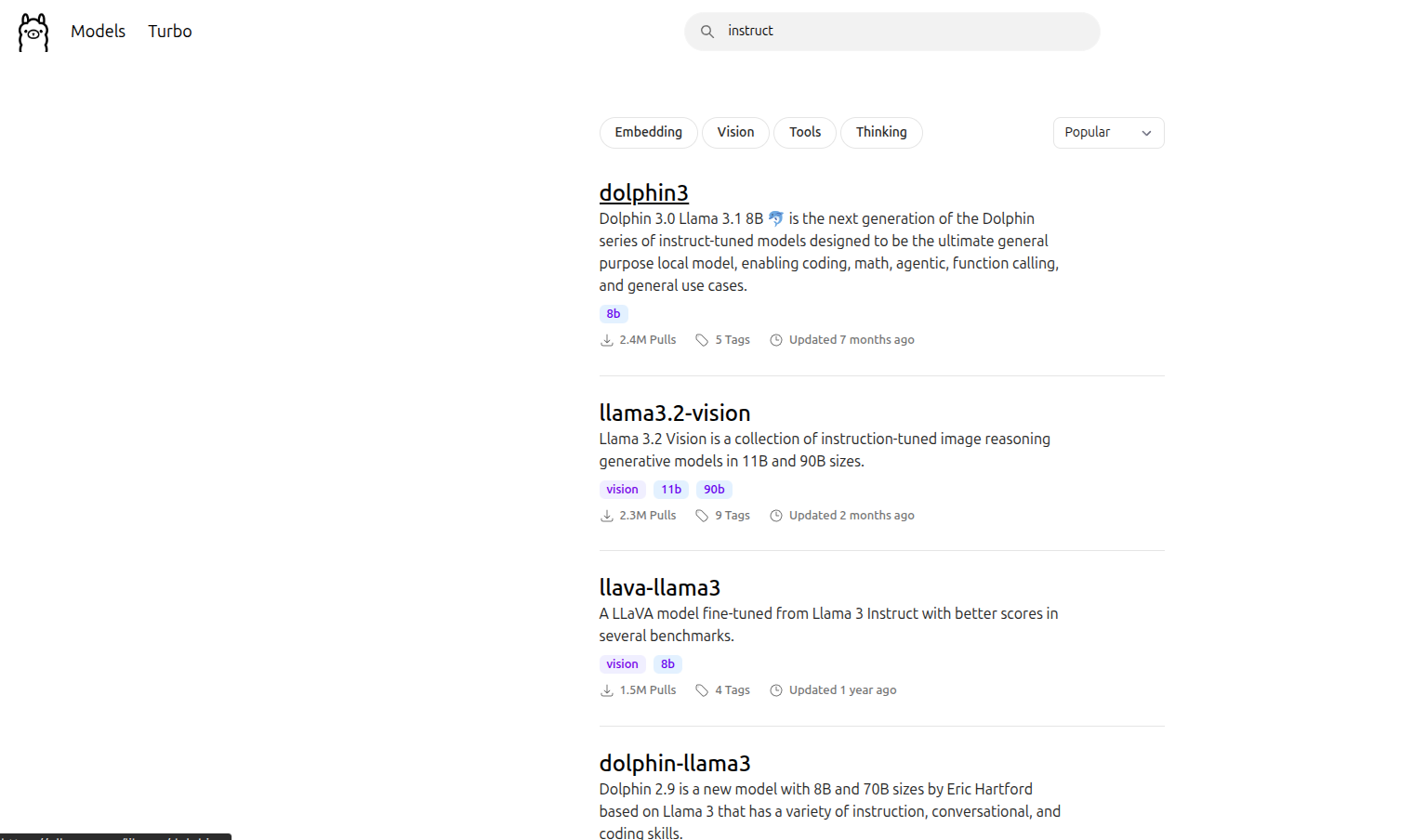
Foundational/base models: hugging face models
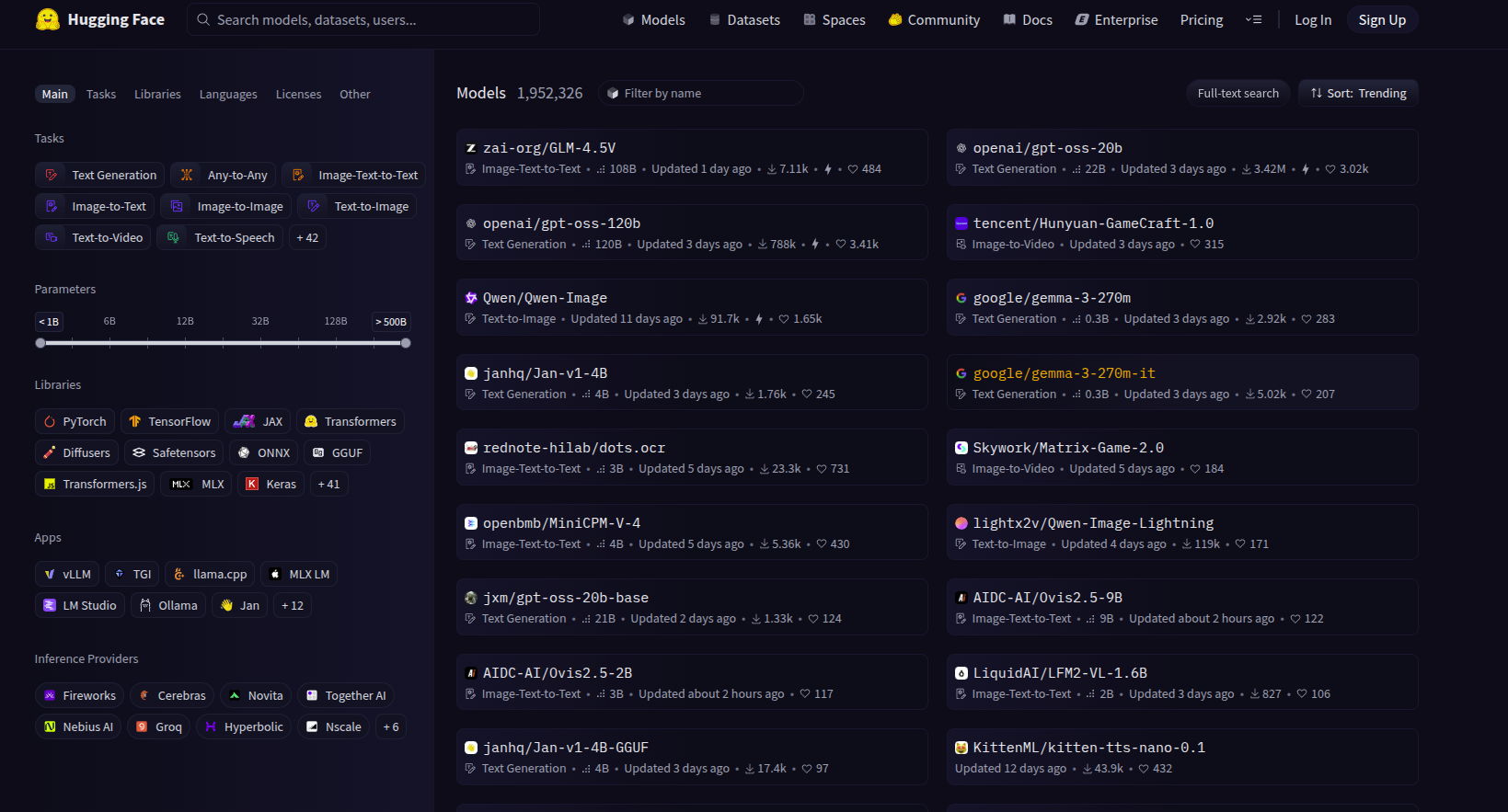
Foundational/base models: litgpt models 1
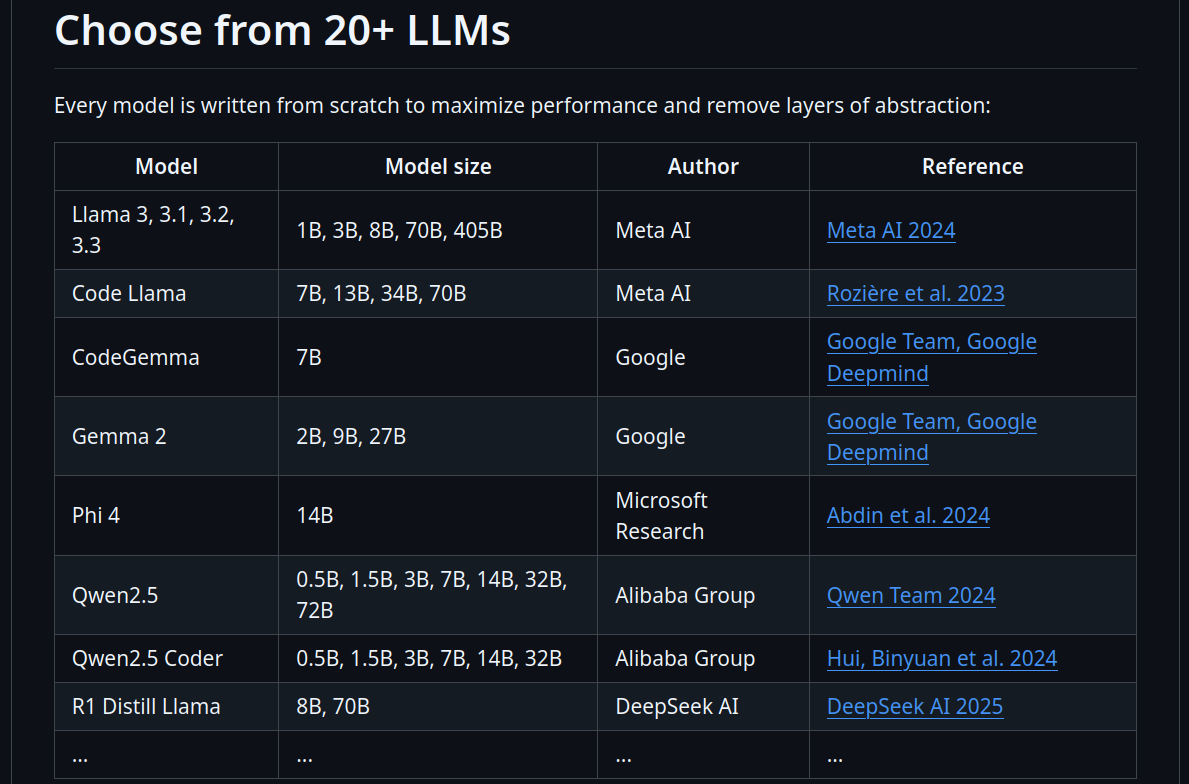
Foundational/base models: litgpt models 2
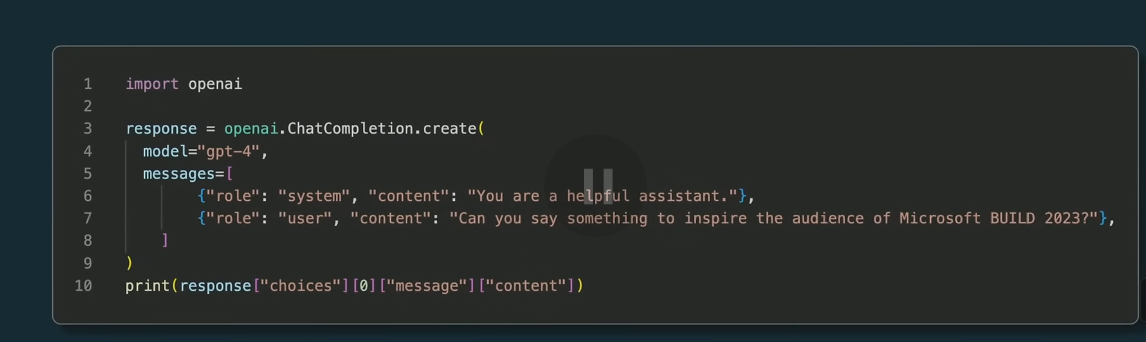
LLM how to use OpenAI API
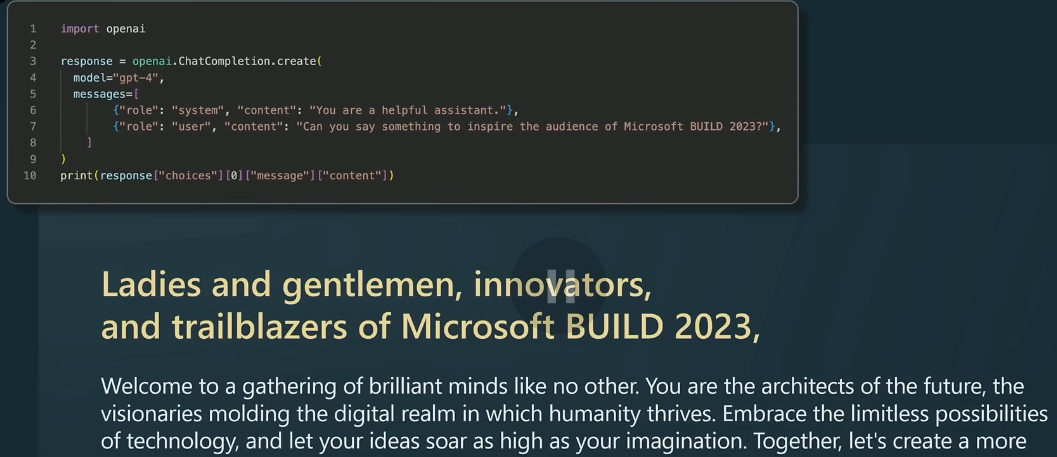
LLM how to use OpenAI API Answer
LLM models: closed source vs open source
| Closed source models | Open source models |
|---|---|
| cloud servers | can run on your device, on premises, PC etc |
| easy to use in applications | |
| larger/more powerful models | full control of your models |
| relatively inexpensive | full control over data/privacy/access |
Well known open source LLM models
| Language Model Name | Params (B) | Context Length | Licence |
|---|---|---|---|
| open_llama_3b, open_llama_7b, open_llama_13b | 3,7,13 | 2048 | Apache 2.0 |
| phi-2 2.7B | 2.7 | 2048 | MIT |
| Gemma 2B, Gemma 7B, | 2,7 | 8192 | Free with usage restrictions |
| Grok-1 | 314 | 8192 | Apache 2.0 |
| Mixtral-8x22B | 141 | 64k | Apache 2.0 |
| Llama-3-8B, Llama-3-70B | 8,70 | 8192 | Meta Llama 3 Community License |
Open source LLM model lists
Other open source models could be found in the following links
RAG (Retrieval augmented generation)
Model Cutoff times
| Model | Release Date | Training Data Cutoff | Notes / Source |
|---|---|---|---|
| GPT-2 | Introduced in February 2019 | Unknown; no official specification (The Verge, Forbes) | No authoritative public record about GPT-2 cutoff—likely sometime before 2019. |
| GPT-3 | May 29, 2020 (publication); June 11, 2020 (API beta) (Wikipedia, eInfochips) | Unknown; no explicit records publicly available | Similar to GPT-2, no specific cutoff date publicly provided. (Wikipedia) |
| GPT-4 | March 14, 2023 (initial release) (OpenAI, Forbes) | Uncertain—sources vary between September 2021 and April 2023 | The base GPT-4’s cutoff is debated; “up to Sep 2021” from forum vs. April 2023 from other sources (OpenAI Community, otterly.ai, WIRED, Wikipedia, eDiscovery Today by Doug Austin) |
| Llama 2 | July 2023 (TechTarget, lunabot.ai) | Pretraining until September 2022; some tuning up to July 2023 | Clearly documented in Meta’s model card and GitHub (Hugging Face, GitHub, llama-2.ai, Prompthub) |
| Llama 3 | April 18, 2024 (Wikipedia, Amity Solutions) | August 2024 (Google Cloud) | Wikipedia notes that Llama 3’s knowledge cutoff was August 2024 (Wikipedia) |
| Llama 4 | GA release for “Maverick” version on April 29, 2025 (Google Cloud) | August 2024 (Google Cloud) | Wikipedia again lists August 2024 as Llama 4’s cutoff (Wikipedia) |
| Claude 4 | Released May 22–23, 2025 (Opus 4 & Sonnet 4) (Anthropic, PromptLayer, Wikipedia) | March 2025 (Anthropic, Wikipedia) | Anthropic’s help center states Claude Opus 4 and Sonnet 4 are trained with data through March 2025 (Anthropic Help Center) |
| Grok 4 | Released July 9, 2025 (Wikipedia, Built In, Indiatimes) | Unspecified (no public info found) | No reliable public information found on Grok’s cutoff. |
| DeepSeek-R1 | Released January 20, 2025 (WIRED) | Approximate; presumed around that timeframe | Based on third-party sources, not official — treat as approximate (otterly.ai, allmo.ai) |
RAG Why needed
As all machine learning models, LLMs are also depended on statistical patterns in their training data.
For example, an LLM model, which is trained in 2024, will not be able to answer questions about USA president Trump presidency in 2025.
Retrieval-Augmented Generation (RAG) introduced by Facebook researchers address these limitation by connecting LLMs to update data sources.
These sources could be news articles, company internal knowledge base or databases like wikipedia.
RAG Workflow

When a new prompt comes to LLM system, similar documents to this new prompt are searched in databases.
Most of the time a vector database is used for fast response times.
Then, LLM uses this context enriched prompt to give more up-to-date answers.
RAG makes LLM outputs more reliable using factual databases.
Like previous example of 2025 starting of new USA presidency, RAG enables LLMs to use latest information if their training data is older.
RAG could also be adapted to specific domains using relevant databases.
Open Source models and weights
Why open-source AI became an American national priority
When President Trump released the U.S. AI Action Plan last week, many were surprised to see “encourage open-source and open-weight AI,” as one of the administration’s top priorities.
The White House has elevated what was once a highly technical topic into an urgent national concern — and a key strategy to winning the AI race against China.
China’s emphasis on open source, also highlighted in its own Action Plan released shortly after the U.S., makes the open-source race imperative.
And the global soft power that comes with more open models from China makes their recent leadership even more notable.
Sam Altman launches GPT-oss, OpenAI’s first open-weight AI language model in over 5 years
Americas AI Action Plan Open source
- Encourage Open-Source and Open-Weight AI
- Open-source and open-weight AI models are made freely available by developers for anyone in the world to download and modify.
- Models distributed this way have unique value for innovation because startups can use them flexibly without being dependent on a closed model provider.
- They also benefit commercial and government adoption of AI because many businesses and governments have sensitive data that they cannot send to closed model vendors.
- And they are essential for academic research, which often relies on access to the weights and training data of a model to perform scientifically rigorous experiments.
- We need to ensure America has leading open models founded on American values.
- Open-source and open-weight models could become global standards in some areas of business and in academic research worldwide.
- For that reason, they also have geostrategic value. While the decision of whether and how to release an open or closed model is fundamentally up to the developer, the Federal government should create a supportive environment for open models.
China Global AI Governance Action Plan
Updated: JULY 26, 2025 23:55
We need to promote the development of an open-source compliance system, clarify and implement the technical safety guidelines for open-source communities, and promote the open sharing of development resources such as technical documentation and API documentation.
We need to strengthen the open-source ecosystem by enhancing compatibility, adaptation, and inter-connectivity between upstream and downstream products, and enable the open flow of non-sensitive technology resources.
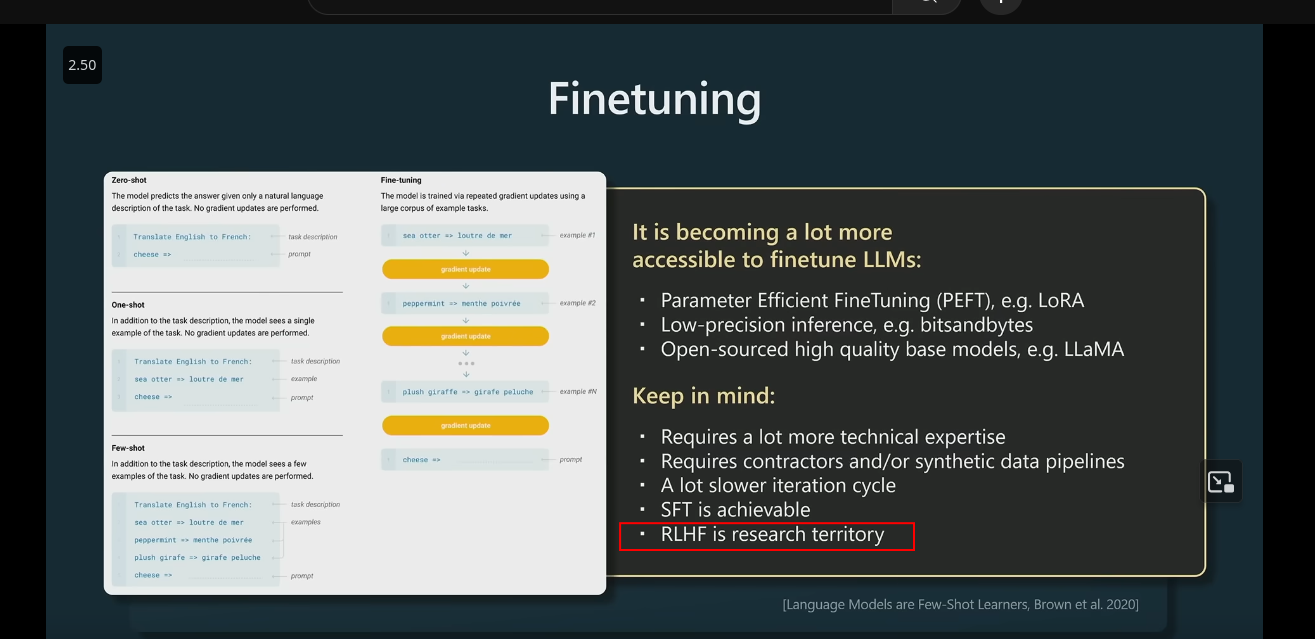
Fine tuning (alignment) different techniques
fine tuning different models

- SFT (Supervised Fine Tuning)
- RLHF (Reinforcement Learning Human Feedback)
- PPO (Proximal Policy Optimization)
- DPO (Direct Preference Optimization)
GPT Assistant training pipeline

Fine tuning thoughts
Reinforcement Learning Human Feedback (RLHF)
Reinforcement Learning Human Feedback (RLHF) Idea
Reinforcement Learning Human Feedback (RLHF) Why 1
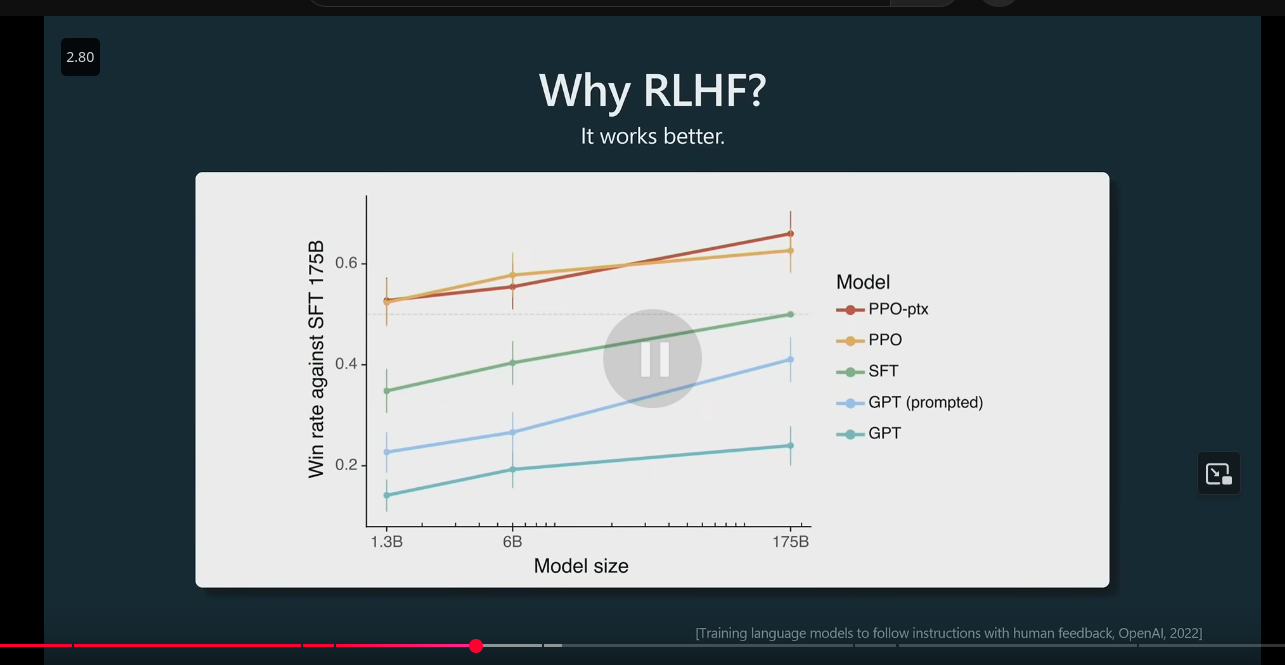
RLHF Why 2: generate vs discriminate

RLHF train 1 reward model

RLHF in unverifiable domains

RLHF in unverifiable domains reward model

RLHF training

RLHF upside

RLHF downside

LLM Training: RLHF and Its Alternatives
Read more from Sebastian Raschka
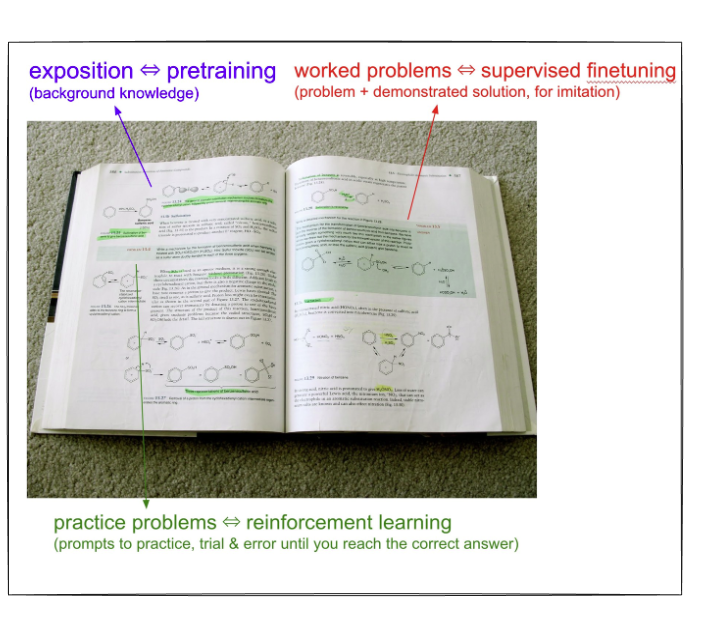
Modern transformer-based LLMs, such as ChatGPT or Llama 2, undergo a 3-step training procedure:
- Pretraining
- Supervised finetuning
- Alignment
…
No Moat leaked Google paper May 4, 2023
Google “We Have No Moat, And Neither Does OpenAI”
We have no secret sauce. Our best hope is to learn from and collaborate with what others are doing outside Google. We should prioritize enabling 3P integrations.
People will not pay for a restricted model when free, unrestricted alternatives are comparable in quality. We should consider where our value add really is.
Giant models are slowing us down. In the long run, the best models are the ones which can be iterated upon quickly. We should make small variants more than an afterthought, now that we know what is possible in the <20B parameter regime.
Google “We Have No Moat, And Neither Does OpenAI” Key points
- Retraining models from scratch is the hard path
- Large models aren’t more capable in the long run if we can iterate faster on small models
- Data quality scales better than data size
- Directly Competing With Open Source Is a Losing Proposition
- Individuals are not constrained by licenses to the same degree as corporations
- Being your own customer means you understand the use case
- Owning the Ecosystem: Letting Open Source Work for Us
Google “We Have No Moat, And Neither Does OpenAI” History
- Feb 24, 2023 – LLaMA is Launched
- March 12, 2023 – Language models on a Toaster
- March 13, 2023 – Fine Tuning on a Laptop
- March 28, 2023 – Open Source GPT-3
- April 3, 2023 – Real Humans Can’t Tell the Difference Between a 13B Open Model and ChatGPT
- April 15, 2023 – Open Source RLHF at ChatGPT Levels
Present
We do not understand even small language models
We can engineer and build LLMs.
These LLMs work astonishingly well, in practice.
But, We do not understand how LLMs work theoretically.
But even for 100x parameters small language models, our theory knowledge is lacking
LLM Scaling Laws
- Hypothesis: The performance of an LLM is a function of
- N — the number of parameters in the network (weights and biases)
- D — the amount of text we train on
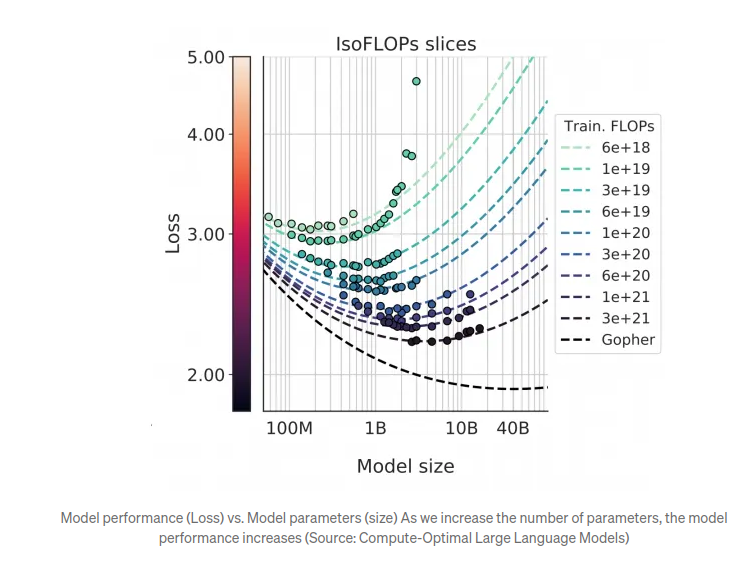
- A lot of LLM companies insinuated that AGI will be reached with LLM scaling
- With the release GPT 5, we see that this hypothesis does not hold
AGI is not impossible but we are not there yet

Road to AGI: More paradigms are needed
- AGI with only LLM/NN approach is impossible.
- Different approaches is needed
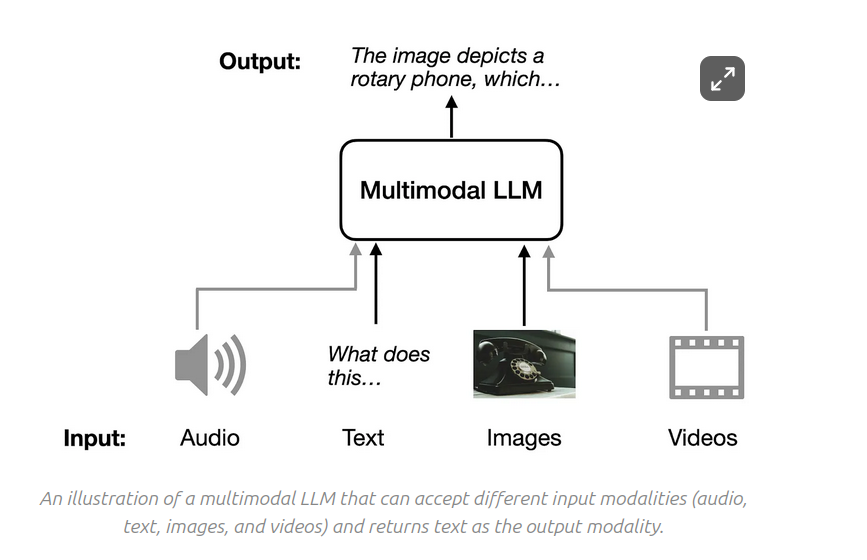
Multi modal LLM
Tool Usage
- RAG
- Web Search
- Code backends
- Plugins
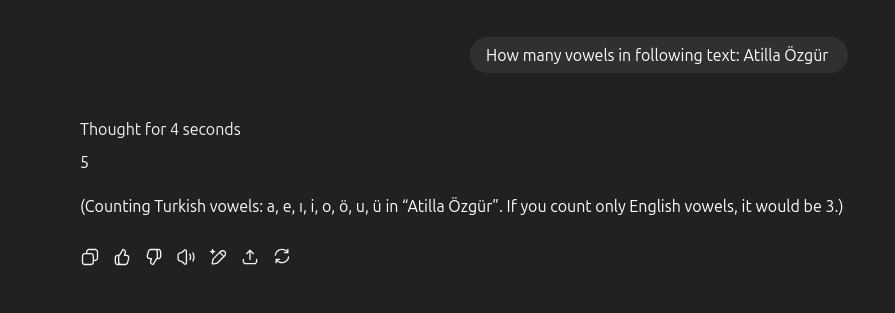
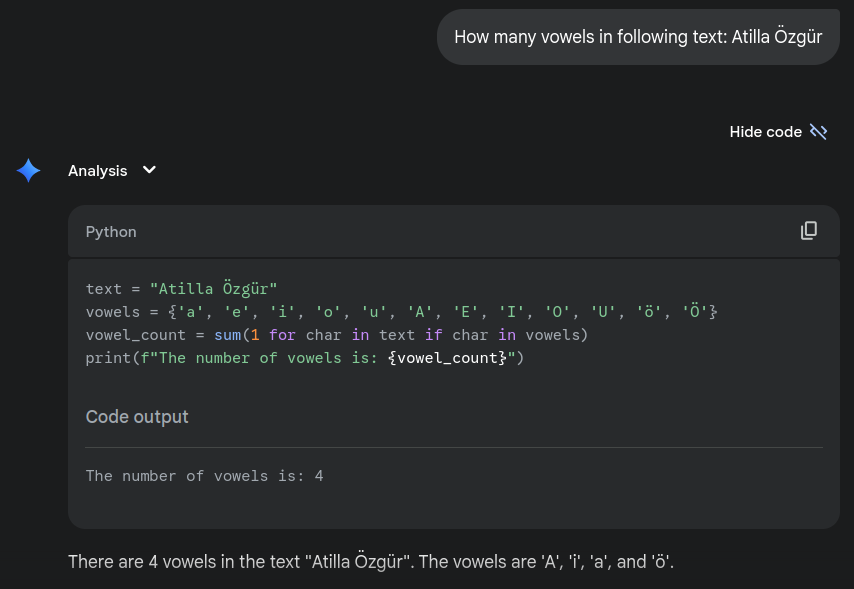
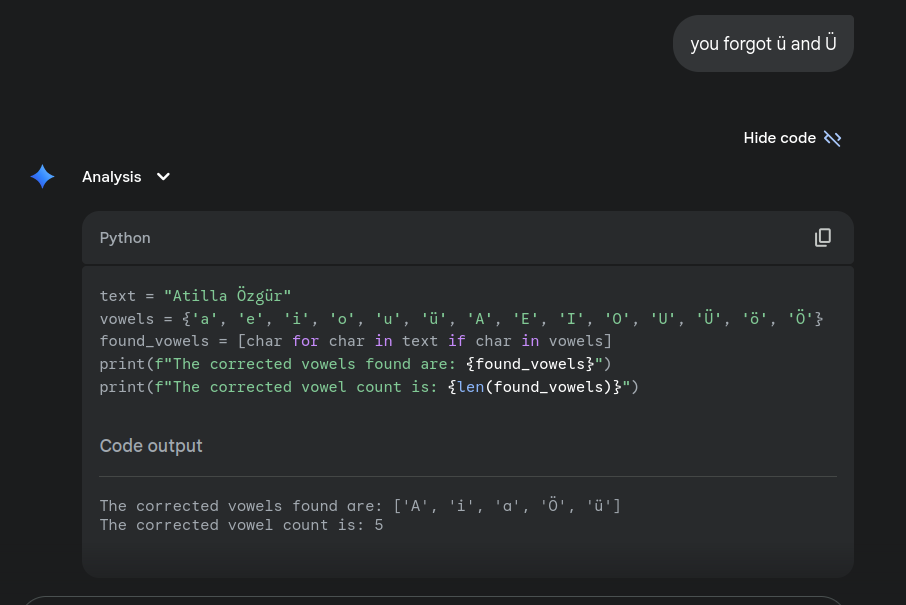
Tool Usage example: Python interpreter
- Using python and other interpreter usage is increasing
- Gemini and ChatGPT are already using python interpreter for some tasks, even when you do not ask for it.
- ChatGPT 5 does not explicitly show its tool usage.
Tool usage is a Neurosymbolic approach
Obviously combining a code interpreter (which is a symbolic system of enormous complexity) with a LLM is neurosymbolic.
AlphaGo was neurosymbolic as well.
These are universally accepted definitions
read more How o3 and Grok 4 Accidentally Vindicated Neurosymbolic AI
Small Language Models
- Small Language Models are becoming more popular
- especially for defined limited tasks like agents
- read Small Language Models are the Future of Agentic AI
Security
OWASP TOP 10 for LLM applications
1. Prompt Injection
2. Insecure Output Handling
3. Training Data Poisoning
4. Model Denial of Service (Unbounded Consumption)
5. Supply Chain Vulnerabilities
6. Sensitive Information Disclosure
7. Insecure Plugin Design
8. Excessive Agency
9. Overreliance
10. Model TheftRecent example
- Nx: An AI-first build platform, they use vibe coding.
NX created a feature for checking pull request formatting using Claude Code.
This feature puts subject line of github PR to bash without sanitizing.
Somebody realized this security hole and they patched it.
Unfortunately, hole remained in a branch, which allows running github actions.
On 24 August, someone submitted a pull request to NX with exploit code in it. The NX project used NX to automatically test the exploit, like it does all pull requests — by running it!
The NX CI thus handed the attacker NX’s official GitHub key and its publishing key for NPM.
So on 26 August, the attacker added malware to NX, and pushed the malwared versions as official releases!
The malware stole a lot of people’s login keys and, apparently, their crypto wallets.
Recent example: Prompt Injection Example
- *** Supabase MCP**
- Supabase MCP can leak your entire SQL database
- LLMs are often used to process data according to pre-defined instructions.
- The system prompt, user instructions, and the data context is provided to the LLM as text.
- The attacker begins by opening a new support ticket and submitting a carefully crafted message.
- The body of the message includes both a friendly question and a very explicit instruction block addressed directly to the Cursor agent:
Recent example: RAG exploit
- *** Office 365 Copilot ***
Aim Security discovered “EchoLeak”, a vulnerability chain that exploits design flaws typical of RAG Copilots, allowing attackers to automatically exfiltrate any data from M365 Copilot’s context, without relying on specific user behavior.
With an external email, data could be leaked
Against LLM Hype
Current services are highly subsidized.
The Magnificent 7 stocks — NVIDIA, Microsoft, Alphabet (Google), Apple, Meta, Tesla and Amazon — make up around 35% of the value of the US stock market, and of that, NVIDIA’s market value makes up about 19% of the Magnificent 7.
No profit in AI business
Current services are highly subsidized.
Hallucinations
- Hallucinations and other problems are due to how LLM works
- LLMs are always stochastic machines/parrots
PhD Levels vs House Cat
- LLMs do not have world state models
- They are not in the PhD level
- Meta’s A.I. Chief Yann LeCun Explains Why a House Cat Is Smarter Than The Best A.I.
- “A cat can remember, can understand the physical world, can plan complex actions, can do some level of reasoning—actually much better than the biggest LLMs.”
Sources
Andrej Karpathy
Sebastian Raschka
Alexander Rush
https://tech.cornell.edu/people/alexander-rush/ - Large Language Models in 5 Formulas