flowchart TD
L("Laplace: Analog")
F("Fourier: Frekans")
Z("Z:Ayrık")
L--> F --> Z -->L
3 Yerleştirmeler (embeddings)
3.1 GPT mimarisinde yerleştirme
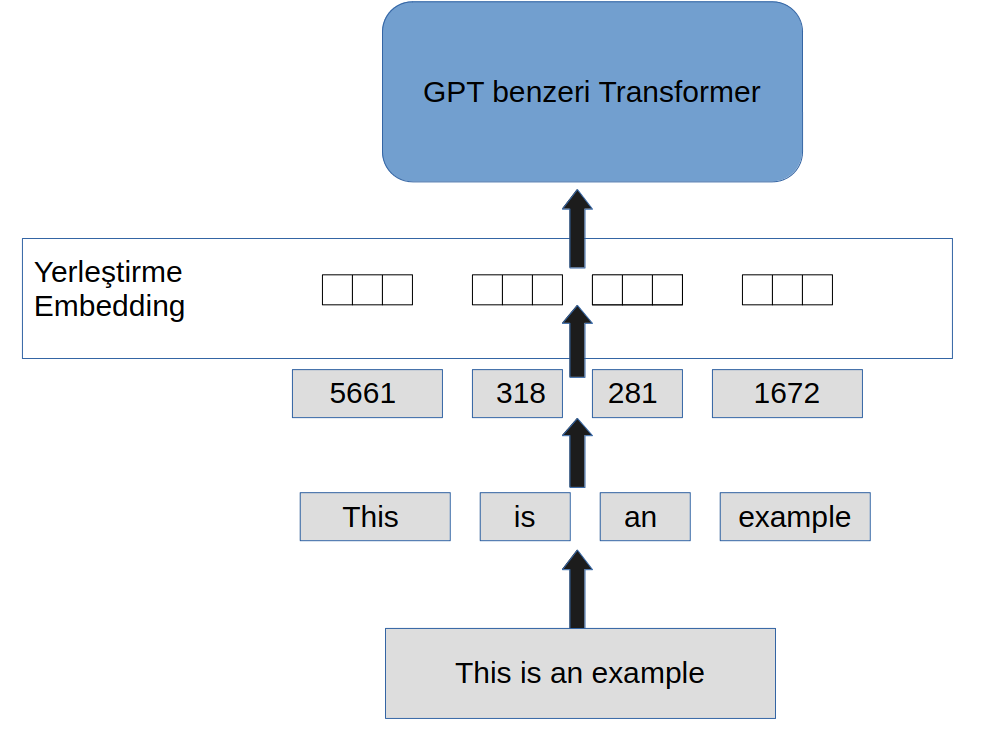
3.2 Giriş
Problem, sayılaştırma (tokenization) sonucunda yazımızı sayılara dönüştürüyoruz ama bu sayılar arasında bir ilişkimiz yok. Örneğin GPT2 transformer dog (köpek) kelimesini 9703, cat kelimesini 9246 ile sayılaştırmaktadır. Aşağıdaki tabloda örnek olarak bazı GPT2 sayılaştırmaları verilmiştir.
| Word (kelime) | GPT2 sayılaştırma |
|---|---|
| dog (köpek) | 9703 |
| cat (kedi) | 9246 |
| kitten (kedi yavrusu) | 74, 2621 |
| apple (elma) | 18040 |
| banana (muz) | 3820, 2271 |
** Örnek: Mühendislik dönüşümleri **
Yerleştirmelerin mantığı mühendislikte kullanılan dönüştürmelere benzer.
Biz 9703 (dog) ve 9246 (cat) ile matematiksel işlem tanımlamakta zorlanırız. Bu sayılar ile oldukları gibi işlem yapmak yerine bu sayılar daha büyük bir yerleştirme uzayına dönüştürüp işlemleri orada yapıp, arkasından tekrar sözlük sayılaştırmalarına (tokenization) döndürmek daha kolay olacaktır.
** Örnek: 5 özellik **
Biz kedi ve köpek’ler hakkında birçok bilgiye sahibiyiz. Örneğin ikisininde 4 ayağı olduğunu, ev hayvanı olduğunu biliyoruz. Yerleştirmelerin amacı aşağıdakine benzeyen bir şekilde bu kelimelerin sayılarına daha büyük bir uzaya dönüştürmektir.
| Kedi | Köpek | Elma | Muz | |
|---|---|---|---|---|
| Kuyruğu Var Mı | 23 | 31 | 1 | 2 |
| 4 Ayaklı | 20 | 19 | 0 | 0 |
| Yenir mi? | 0 | 0 | 19 | 21 |
| Ses Çıkarır | 18 | 12 | 0.5 | 0.2 |
| Ev Hayvanı | 32 | 34 | 5 | 6 |
Buradaki özellik boyutu 5 örnek olarak verilmiştir. Yapay sinir ağları bu özellikleri kendisi öğrenir. Normalde bu sayılar çok daha büyüktür. Örneğin önceden eğitilmiş kelime yerleştirme Gensim glove-wiki-gigaword-100 modeli 100 boyutludur.
Öğrenilen bu uzayda birbirine yakın kelimelerin (kedi, köpek) daha yakın olması amaçlanmaktadır.
Gensim glove-wiki-gigaword-100 modeli wikipedia verisinde eğitilmiştir. Bu modelin yerleştirmelerini PCA kullanarak 2 boyuta indirgeyerek görselleştirebiliriz. Aşağıda bu işlemin örnek bir sonucunu görebilirsiniz.
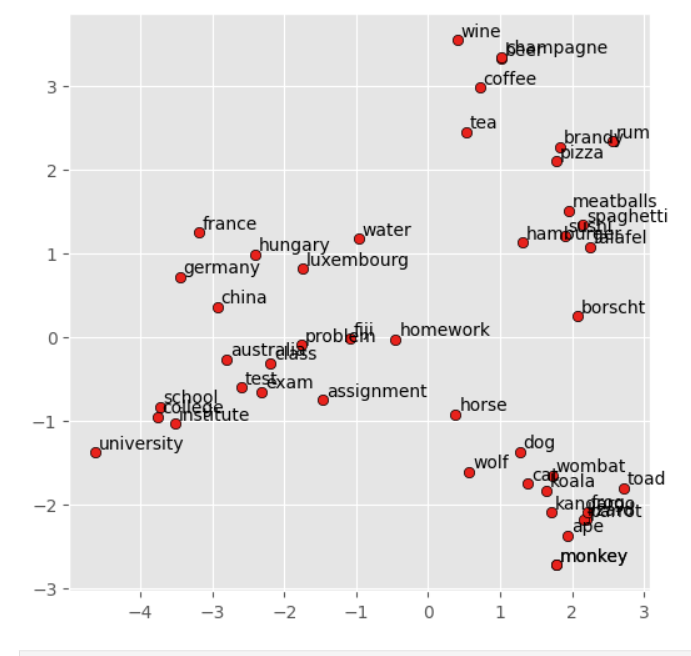
Yukarıdaki resimde cat ve dog kelimelerinin birbirine yakın olduğunu ve aynı zamanda alaklı kelimelerinde indirgendikleri 2 boyutta bile yakın olduklarına dikkat ediniz.
3.3 Yerleştirme Boyutu ve LLM parametre sayısı
LLM modellerinin parametre sayısını belirleyen kıstaslardan biride yerleştirme boyutlarıdır. Aşağıda bilinen bazı LLM modellerinin yerleştirme boyutları verilmiştir.
| Model Family | Variant | Parameters | Embedding Size |
|---|---|---|---|
| GPT-1 | 117M | 117M | 768 |
| GPT-2 | Small | 124M | 768 |
| Medium | 355M | 1024 | |
| Large | 774M | 1280 | |
| XL | 1.5B | 1600 | |
| GPT-3 | Ada | 350M | 1024 |
| Babbage | 1.3B | 2048 | |
| Curie | 6.7B | 4096 | |
| Davinci | 175B | 12288 | |
| GPT-4 / GPT-4o | — | undisclosed | (not public) |
| LLaMA 1 / 2 | 7B | 7B | 4096 |
| 13B | 13B | 5120 | |
| 33B | 33B | 6656 | |
| 65B | 65B | 8192 | |
| LLaMA 3 | 8B | 8B | 4096 |
| 70B | 70B | 8192 | |
| Mistral | 7B | 7B | 4096 |
| Mixtral | 8×7B (MoE) | 46.7B total | 4096 (per expert) |
| DeepSeek | 7B | 7B | 4096 |
| 67B | 67B | 8192 | |
| Qwen 1 | 7B | 7B | 4096 |
| 14B | 14B | 5120 | |
| 72B | 72B | 8192 | |
| Qwen 1.5 | 0.5B | 0.5B | 1024 |
| 1.8B | 1.8B | 2048 | |
| 4B | 4B | 2560 | |
| 7B | 7B | 4096 | |
| 14B | 14B | 5120 | |
| 32B | 32B | 7168 | |
| 72B | 72B | 8192 | |
| Qwen 3 | Embedding-0.6B | 0.6B | 1024 |
| Embedding-4B | 4B | 2560 | |
| Embedding-8B | 8B | 4096 | |
| Dense-32B | 32B | 4096 | |
| Gemini | 1 / 1.5 | various | not public (est. 8k–16k) |
| Claude | 2 / 3 | various | not public (est. 8k–16k) |
3.4 Yerleştirme Oyun alanı
https://andkret.github.io/embedding-playground/
kelime yerleştirme için etkileşimli web uygulaması: turbomaze.github.io/word2vecjson, Kaynak kodu.
Bu uygulama, word2vec’in 10.000 kelimelik bir alt kümesini kullanır. Kelimeleri ve 300 uzunluğundaki sayı dizisini inceleyin.
3.5 Kelime Yerleştirmeleri
- word2vec
- gensim
3.6 Önceden Eğitilmiş Örnek 1 Kelime Vektörleri: Gensim
- notebooks/Gensim_word_vector_visualization
3.7 Önceden Eğitilmiş Örnek 2: Sentence Transformer
#embeddings-sentence-transformer.py
from sentence_transformers import SentenceTransformer
# 1. Load a pretrained Sentence Transformer model
model = SentenceTransformer("all-MiniLM-L6-v2")
# The sentences to encode
sentences = [
"The weather is lovely today.",
"It's so sunny outside!",
"He drove to the stadium.",
]
# 2. Calculate embeddings by calling model.encode()
embeddings = model.encode(sentences)
print(embeddings.shape)
# [3, 384]
# 3. Calculate the embedding similarities
similarities = model.similarity(embeddings, embeddings)
print(similarities)
# tensor([[1.0000, 0.6660, 0.1046],
# [0.6660, 1.0000, 0.1411],
# [0.1046, 0.1411, 1.0000]])3.8 Kelime Vektörleri Eğitim Örneği
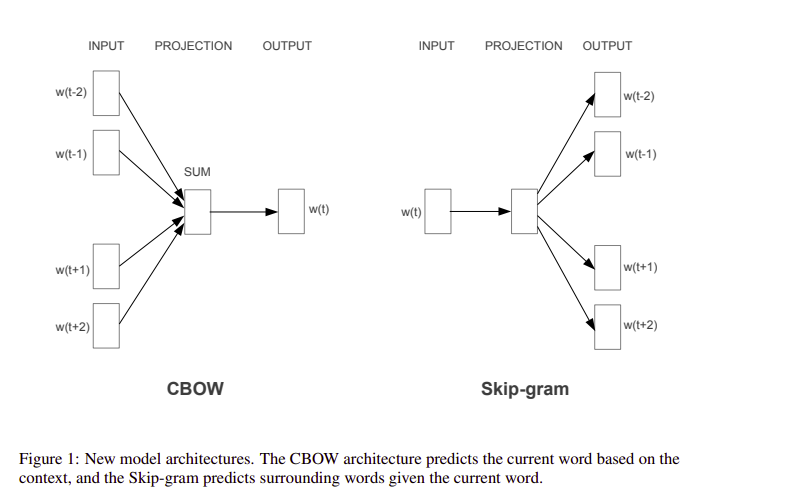
import torch
import torch.nn as nn
import torch.optim as optim
import random
from collections import Counter
# ----------------------------
# 1. Prepare Data
# ----------------------------
corpus = [
"we are what we repeatedly do",
"excellence then is not an act but a habit",
"the unexamined life is not worth living",
"to be yourself in a world that is constantly trying to make you something else is the greatest accomplishment"
]
def tokenize(text):
return text.lower().split()
tokenized_corpus = [tokenize(sentence) for sentence in corpus]
vocab = Counter(word for sentence in tokenized_corpus for word in sentence)
# Add <PAD> token to vocab for context padding
print(vocab)
vocab["<PAD>"] = 1 # ensure it exists
word2idx = {w: idx for idx, (w, _) in enumerate(vocab.items())}
idx2word = {idx: w for w, idx in word2idx.items()}
vocab_size = len(vocab)
# Generate CBOW training pairs with fixed-length context
window_size = 2
pairs = []
context_len = 2 * window_size # fixed size
for sentence in tokenized_corpus:
for center_pos, center_word in enumerate(sentence):
context = []
for w in range(-window_size, window_size + 1):
context_pos = center_pos + w
if w == 0 or context_pos < 0 or context_pos >= len(sentence):
continue
context.append(word2idx[sentence[context_pos]])
# Pad if context shorter than full size
while len(context) < context_len:
context.append(word2idx["<PAD>"])
pairs.append((context, word2idx[center_word]))
print(f"Total training pairs: {len(pairs)}")
#print(pairs)
#pair_words = [([idx2word[id] for id in t[0]],idx2word[t[-1]]) for t in pairs]
#print(pair_words)
# ----------------------------
# 2. CBOW Model
# ----------------------------
class CBOW(nn.Module):
def __init__(self, vocab_size, embedding_dim):
super(CBOW, self).__init__()
self.embeddings = nn.Embedding(vocab_size, embedding_dim)
self.linear = nn.Linear(embedding_dim, vocab_size)
def forward(self, context_words):
embeds = self.embeddings(context_words) # (batch, context_len, embed_dim)
avg_embeds = embeds.mean(dim=1) # (batch, embed_dim)
out = self.linear(avg_embeds) # (batch, vocab_size)
return out
# ----------------------------
# 3. Train
# ----------------------------
embedding_dim = 50
batch_size = 8
epochs = 50
model = CBOW(vocab_size, embedding_dim)
loss_fn = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.01)
for epoch in range(epochs):
random.shuffle(pairs)
total_loss = 0
for i in range(0, len(pairs), batch_size):
batch = pairs[i:i+batch_size]
context_batch = torch.tensor([p[0] for p in batch], dtype=torch.long)
target_batch = torch.tensor([p[1] for p in batch], dtype=torch.long)
optimizer.zero_grad()
output = model(context_batch)
loss = loss_fn(output, target_batch)
loss.backward()
optimizer.step()
total_loss += loss.item()
print(f"Epoch {epoch+1}, Loss: {total_loss:.4f}")
# ----------------------------
# 4. Test Embeddings
# ----------------------------
def get_embedding(word):
idx = word2idx[word]
return model.embeddings.weight.data[idx]
print("\nEmbedding for 'excellence':")
print(get_embedding("excellence"))3.9 Kitap Kodu
3.10 Tavsiye Vidyolar
Başlıklar çevrilmemiştir.