flowchart LR
Input[Example input here] -->|Tokenize decode| InputTokens
InputTokens["16281, 5128, 994"] --> LLM
LLM("LLM")
LLM -->OutputTokens
OutputTokens["16281, 5072, 994"] -->|Tokenize decode| Output
Output["Example output here"]
2 Sayılaştırma (Tokenization)
Bilişim sözlüğü çeviri olarak simgeleştirme vermiş ama bana göre sayılaştırma LLM bağlamında daha anlamlı.
2.1 Niçin
Tüm makine öğrenme yöntemleri gibi, yapay sinir ağları da sadece sayılar ile çalıştığı için verilen metinleri sayılara çevirmek gerekiyor.
2.2 Görselleştirme
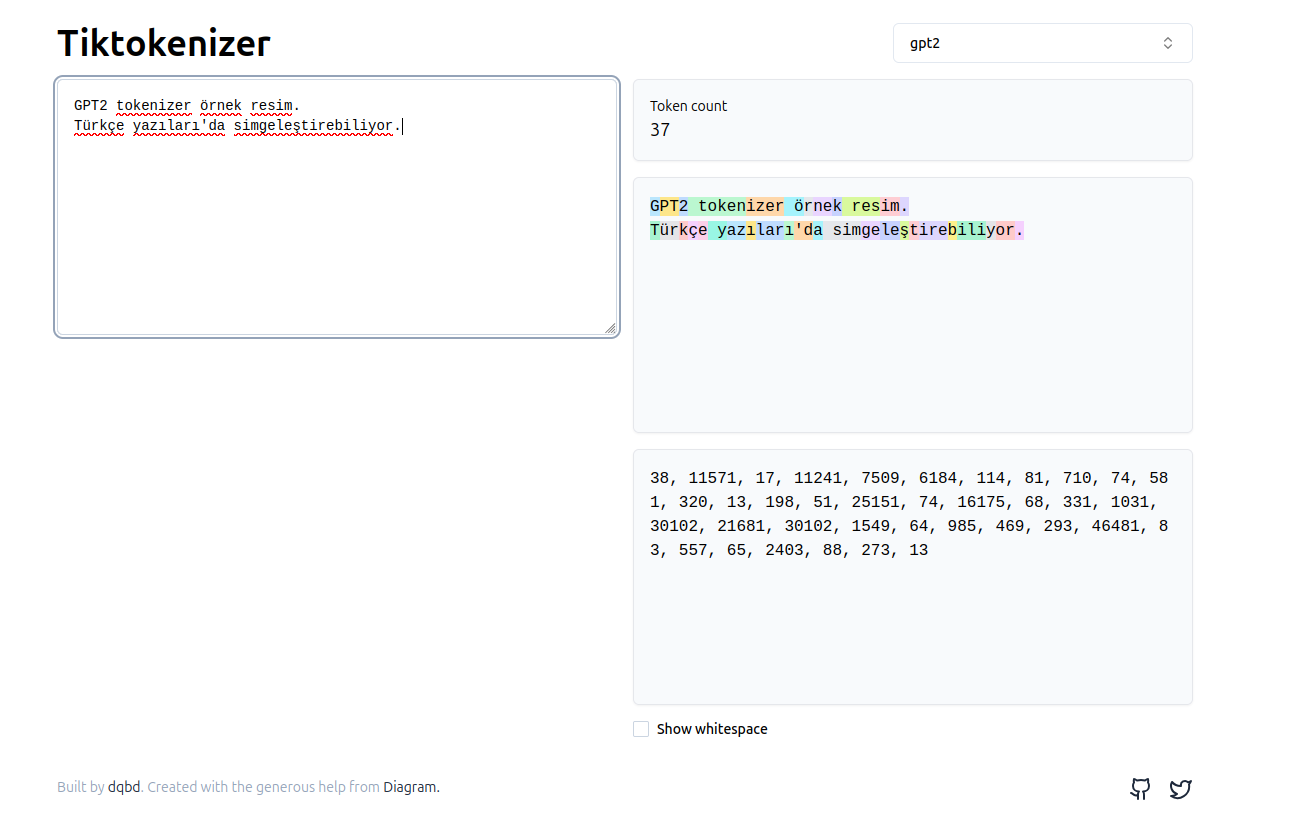
- sadece gpt2 görselleştirme aracı kodu açık ve internet olmadan çalıştırılabiliyor.
2.2.1 Örnek simgeleştirme yazısı
# tokenization-example-string-Andrej-Karpathy
Tokenization is at the heart of much weirdness of LLMs. Do not brush it off.
127 + 677 = 804
1275 + 6773 = 8041
Egg.
I have an Egg.
egg.
EGG.
만나서 반가워요. 저는 OpenAI에서 개발한 대규모 언어 모델인 ChatGPT입니다.
궁금한 것이 있으시면 무엇이든 물어보세요.
for i in range(1, 101):
if i % 3 == 0 and i % 5 == 0:
print("Fifteen")
elif i % 3 == 0:
print("Three")
elif i % 5 == 0:
print("Five")
else:
print(i)
Merhaba buradan sonraki yazı Andrej Karpathy'e ait değildir.
hello
hello
HELLO
Türkçe örnek olması için eklenmiştir.
2.3 Neden önemli?
Andrej Karpathy 2 saatlik Let’s build the GPT Tokenizer sunumunda aşağıdaki cümle ile başlamaktadır ve arkasından aşağıdaki tablo verilmektedir.
Sayılaştırma (Tokenization), LLM'lerin birçok tuhaflığının merkezinde yer alır.
Bunu göz ardı etmeyin.| Soru | Cevap |
|---|---|
| LLM neden kelimeleri heceleyemiyor? | Sayılaştırma |
| LLM neden bir dizeyi ters çevirmek gibi çok basit dize işleme görevlerini yapamıyor? | Sayılaştırma |
| LLM neden İngilizce dışındaki dillerde (örneğin Japonca) daha kötü? | Sayılaştırma |
| LLM neden basit aritmetikte kötü? | Sayılaştırma |
| GPT-2 Python’da kodlama yaparken neden gereğinden fazla sorun yaşadı? | Sayılaştırma |
| LLM’im “<endoftext” dizesini gördüğünde neden aniden durdu? | Sayılaştırma |
| Sonraki boşluk” hakkında aldığım bu garip uyarı nedir? | Sayılaştırma |
| LLM’ye “SolidGoldMagikarp” hakkında soru sorduğumda neden çöküyor? | Sayılaştırma |
| LLM’lerde neden JSON yerine YAML kullanmayı tercih etmeliyim? | Sayılaştırma |
| LLM neden uçtan uca dil modellemesi değil? | Sayılaştırma |
| Acının asıl kaynağı nedir? | Sayılaştırma |
2.4 Sayılaştırma Türleri
flowchart TD
T{Tokenization}
T -->|Character based| C
C["`Unicode
n-grams`"]
T -->|Word based| W
W["`word to integers
bag of words
one-hot-encoding`"]
T -->|Sub word based| SW
SW["` Byte pair encoding
Sentence Piece`"]
Karakter tabanlı
- unicode
- n-grams (karakter tabanlı 1-n grams)
Kelime Tabanlı
- Kelimeden tamsayılara (Word to integers). Örnek kod: SimpleTokenizerV1
- Bag of words (uni-gram word based)
- one-hot-encoding
alt kelime (hece benzeri) tabanlı
- Byte pair encoding (GPT versions)
- Sentence piece (LLama versions)
Sözlük büyük olduğunda, kodlanmış sayılar daha kısa olur. Çünkü çoğu sözlük, en çok kullanılan kelimeleri tek bir sayıya kodlamak için frekans analizi kullanır. Bu durumda, LLM parametre sayısı daha az olacaktır.
Sözlük küçük olduğunda, girdi yazısı daha uzun bir sayı kümesi ile kodlanacaktır. LLM parametre sayısı azalır ama bir sonraki sayı (token) tahmini zorlaşır.
2.4.1 Unicode kendisi kullanma
- Sözlük geniş
- Unicode standardı canlı ve değişiyor.
- Bu durumda boyutları değişiyor.
- Yeni gelen Unicode sembollerde sorun yaşanacaktır.
Örneğin Anadolu hiyeroglifleri, emojiler … eklendi
- 𔐀 𔐁 𔐂 𔐃 𔐄 𔐅
- 👀 👁️ 👂 👃 👄 👅 👆 👇 👈 👉 👊 👋 👌 👍 👎 👏
utf8,utf16,utf32 gibi farklı standartlar var.
- unicode wikipedia Sürüm 16.0, çeşitli sıradan, edebi, akademik ve teknik bağlamlarda kullanılan 154.998 karakteri ve 168 betiği tanımlar.
2.5 Notebook SimpleTokenizer
Example notebook for SimpleTokenizer
2.6 Özel Durum Simgeleri (Special context tokens)
| Kısaltma | Tam Adı | Not |
|---|---|---|
| [BOS] | beginning of sequence/Yazı başlangıcı | |
| [EOS] | end of sequence/Yazı bitişi | Genellikle farklı yazıları ayırmak için kullanılır. Örneğin wikipedia makaleleri |
| [PAD] | padding/dolgulama | Eğitim sırasında batch büyüklüğüne göre en uzun cümle uzunluğuna göre kısa cümlelerin dolgulanması gerekir. |
| [UNK] | Unknown/Bilinmeyen | Bilinmeyen kelimeler için |
GPT2 dolgulama ve yazı bitişi için aynı simge olan <|endoftext|> kullanmaktadır. GPT2, sayılaştırma algoritması olarak BPE kullandığı için [UNK] bilinmeyen simgesine ihtiyaç duymamaktadır.
2.7 Çift bayt kodlama (Byte pair encoding)
- Byte pair encoding wikipedia örneği
Örnek olarak aşağıdaki veriyi kodlalım.
aaabdaaabacaa çifti en çok geçtiği için, onun yerine Z simgesi verilcektir. Bu durumda aşağıdaki veri ve sözlük oluşturulacaktır.
ZabdZabac
Z=aaAynı süreç tekrarlanır ve ab yerine Y yerleştirilir.
ZYdZYac
Y=ab
Z=aaBu veride en fazla tekrar eden ZY çifti, X ile değiştirilir.
XdXac
X=ZY
Y=ab
Z=aaBüyük verilerde sözlük büyüklüğüne görede kodlama durabilir. Örneğin en fazla 10 simge kullanılacaktır denilebilir. GPT2 sayılaştırma sözlük boyutu 50257’dir.
2.8 Notebook Tiktoken Tokenizer GPT2
Example notebook for Tiktoken Tokenizer
2.9 Sorunlar tekrar
- Heceleme
strawberry
heceleme- Aritmetik, toplama çıkarma
127 + 677 = 804
1275 + 6773 = 8041- Büyük küçük harf
hello
hello
HELLO- İngilizce harici diller
Merhaba Büyük Dil Modelleri dersine giriş- Python kodlama problemi: GPT2 vs cl100_base
for i in range(1, 101):
if i % 3 == 0 and i % 5 == 0:
print("Fifteen")
elif i % 3 == 0:
print("Three")
elif i % 5 == 0:
print("Five")
else:
print(i)- JSON vs YAML
JSON örnek:
{"name":"John", "age":30, "car":null}YAML versiyonu:
---
name: John
age: 30
car: 2.9.1 SolidGoldMagikarp
Bu bir reddit kullanıcısı. ChatGPT 14 Şubat 2023’ten önce SolidGoldMagikarp hakkında soru sorulduğu zaman hata veriyordu. GPT3 için BPE algoritması eğitilirken reddit üzerinden alınan bir metin grubu kullanılmış. SolidGoldMagikarp bu yazı grubu içinde çok fazla yazının sahibi.
Tahminlere göre, Sayılaştırma veri seti ile LLM veri seti farklı. SolidGoldMagikarp sayısı (token), LLM veri setinde yok. Bu yüzden girdi olarak verildiğinde C dilinde oluşan atanmamış bellek (Un-allocated memory) hatası gibi bir şey oluyor. Daha fazlası için bakınız:
- SolidGoldMagikarp article
- https://www.beren.io/2023-02-04-Integer-tokenization-is-insane/
- https://www.lesswrong.com/posts/aPeJE8bSo6rAFoLqg/solidgoldmagikarp-plus-prompt-generation
- https://www.lesswrong.com/posts/Ya9LzwEbfaAMY8ABo/solidgoldmagikarp-ii-technical-details-and-more-recent
- https://aizi.substack.com/p/explaining-solidgoldmagikarp-by-looking
- https://deconstructing.ai/deconstructing-ai%E2%84%A2-blog/f/the-enigma-of-solidgoldmagikarp-ais-strangest-token
2.10 LLM Modellerinin Tokenizasyon Sözlük Boyutları
ChatGPT 5 ile üretilmiştir.
| Model | Vocabulary Size (tokens) | Notes / Source |
|---|---|---|
| GPT-2 | 50,257 | Byte-level BPE, includes base vocabulary with merges and merges count (Rohan’s Bytes) |
| GPT-3 | ~50,257 | Same tokenizer as GPT-2; widely cited (Rohan’s Bytes) |
| GPT-4 | ~50,000 (not officially disclosed) | No official figure; predecessor GPT-3 had ~50k (Rohan’s Bytes) |
| LLaMA 2 | 32,000 | Standard for LLaMA-2 models (Planet Banatt) |
| LLaMA 3 | 128,000 | Documented token vocabulary (Reddit, Rohan’s Bytes) |
| LLaMA 4 | Not publicly disclosed | No data available |
| Claude (Anthropic) | Not publicly disclosed | No definitive source; earlier anecdotal “~65k” figure unverified |
| Grok (xAI) | Not publicly disclosed | No reliable number found |
| DeepSeek LLM (7B / 67B) | 102,400 | Byte-level BPE, includes English and Chinese; vocabulary size explicitly stated (Wikipedia) |
| DeepSeek-V2 / V2-Lite / V2.5 | Presumably same (102,400) | Not explicitly stated, but likely reused the original LLM tokenizer |
| DeepSeek-V3 | 128,000 | Uses Byte-level BPE with an extended vocabulary of 128K tokens (arXiv, Medium) |
2.11 Kaynak Vidyolar
2.12 Kütüphaneler
- sentencepiece Tokenizer Google: LLaMa, some Google LLMs
- tiktoken Tokenizer OpenAI: GPT2, GPT4, ….